Preface#
I seem to have a tendency to view myself as a machine, often observing myself from an outsider's perspective, integrating various modules, and continuously tinkering and optimizing. When a certain behavioral pattern or habit that I have built suddenly proves effective at a certain moment, it brings a sense of joy. Conversely, when it stops functioning due to external influences or my own state, it creates a profound discomfort as if a sense of order has been disrupted.
As an efficiency tool enthusiast, my personal knowledge management and information management can be said to be the most important part of myself. I didn't initially intend to write this article; there are too many precedents and practices before me, and I am merely making slight adjustments and optimizations based on the foundations laid by others. I often lack the confidence to share. However, this week, after rebuilding and optimizing my knowledge management system, I felt happy and had an impulse to document it. What started as a brief mention in my weekly report turned into this article as I found myself unable to stop writing.
In fact, I have often mentioned information output in my weekly reports, so this article will also cover some previous content and finally fill in the parts about information acquisition and knowledge management, serving as a comprehensive overview. The theoretical parts, such as the "Feynman Technique" and "Zettelkasten Method," have many excellent introductory articles, so I won't spend time introducing them here. Instead, I will elaborate on the software tools I use in practice, hoping to be of help to everyone.
Information Acquisition and Management#
I don't know when it started, but I can clearly feel my dependence on information from the online world. Unlike gaming addiction or the often-criticized short video algorithm opium, my dependence is not about mindlessly scrolling or escaping anxiety; rather, it is a thirst for information acquisition that has even internalized into a lifestyle. Because I have confidence in my ability to filter and digest information, I have not spent much effort on input sources and organization.
As I have become interested in more and more fields, information has accumulated, and sometimes merely browsing and skimming exceeds my memory capacity. Often, this information remains scattered in my notes or in some corner of my mind, not becoming part of my internalized knowledge, making it difficult to recall or retrieve later. Thus, I reorganized my information acquisition methods.
Classification of Information Sources#
My information sources can be categorized into the following major types:
- Random Thoughts
- Information Streams
- Focused Reading
Random Thoughts#

In daily life, work, study, or at any moment, I sometimes have random thoughts that are unrelated to what I am currently doing or are completely out of the blue, but may be useful at some point in the future. Since I usually don't stray too far from my computer, I typically record these in Logseq's Journal. Sometimes, I might temporarily post them in a WeChat group with only myself or in Telegram's Saved Messages, and later add more details.
Information Streams#
From the moment I wake up each day, I am engulfed by information streams from various platforms. The most challenging aspect of relying on the online world is the struggle with social media and algorithms. On one hand, I need to avoid being overwhelmed by anxiety-inducing information or the "Peer Pressure" of my social circle; on the other hand, I must be wary of the information bubble constructed by algorithms. To be honest, this is quite difficult to achieve. Even though I possess some restraint and filtering abilities and consciously try to do so, I still find it hard to avoid being distracted or guided by them.
I ultimately adopted a simple yet effective approach—turning off the WeChat Moments entrance and most software notifications, and limiting the number of platforms that are purely for information acquisition (like Bilibili, Weibo, etc.) to under 100. If I add new ones, I filter and optimize my previous follows to reduce irrelevant content interference. Based on this, I use RSS subscriptions, which may seem a bit old-fashioned, but I have subscribed to fewer than 50 websites, most of which are blogs or personal sites, and I regularly filter them to reduce my daily feeds. However, I generally skim through the titles or do a preliminary browse of the articles in this feeds list.

Initially, I set up a Miniflux service to fetch these, using an RSS-to-Telegram-Bot to push notifications. Recently, after starting to use Readwise Reader and finding it very user-friendly, I migrated this part over. I use a built-in management mode in Readwise Reader, categorized into three types:
- Later
- Shortlist
- Archive
I scan the Feeds panel daily, adding articles of interest to Later for later reading. Of course, based on past experience, articles left in Later for too long often turn into "never read later," so I am very restrained during filtering, only adding articles that I find very interesting and that I will read soon. I also make it a point to clean up the Later list in the evenings.
We are also pushed various information from all corners of social media, and I particularly pay attention to these categories:
- Interesting viewpoints/tweet threads
- Articles of interest
- Useful resources
For interesting viewpoints or comments, I usually do not add them to the corresponding lists or favorites in software. Instead, I copy their content into Logseq's Journal and tag them accordingly. Many software (including Readwise Reader) offer ways to save Twitter threads or other convenient methods for saving tweets, but I prefer to copy and organize them myself, recording them in a few sentences rather than just saving a link. This seemingly deliberate extra step allows me to reflect on these viewpoints, avoiding being overly influenced by strongly guided or emotional opinions, and it is more beneficial for digesting information and internalizing it into my own thoughts.
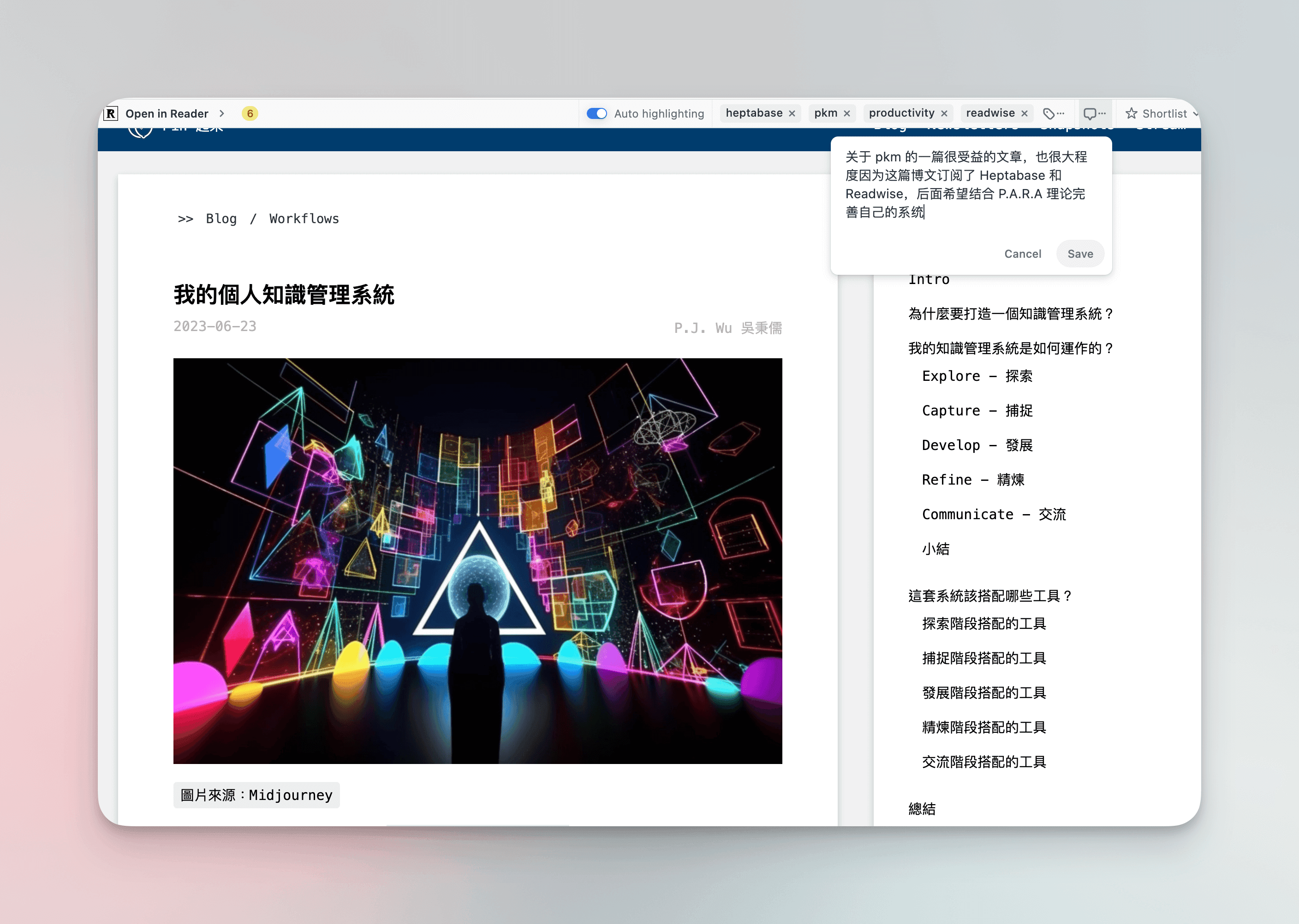
For articles that interest me, I read or save them using Readwise's Chrome extension. My requirement for this part is to tag and take notes on each article, with the notes mainly describing why I chose to read that article.
If I only need to skim or acquire information from certain articles, I add them to the Later list, while those I read closely go into the Shortlist, and I must highlight some meaningful quotes, also trying to add my own evaluations and thoughts to the highlights. All of this can be done directly in the extension, making it very convenient.
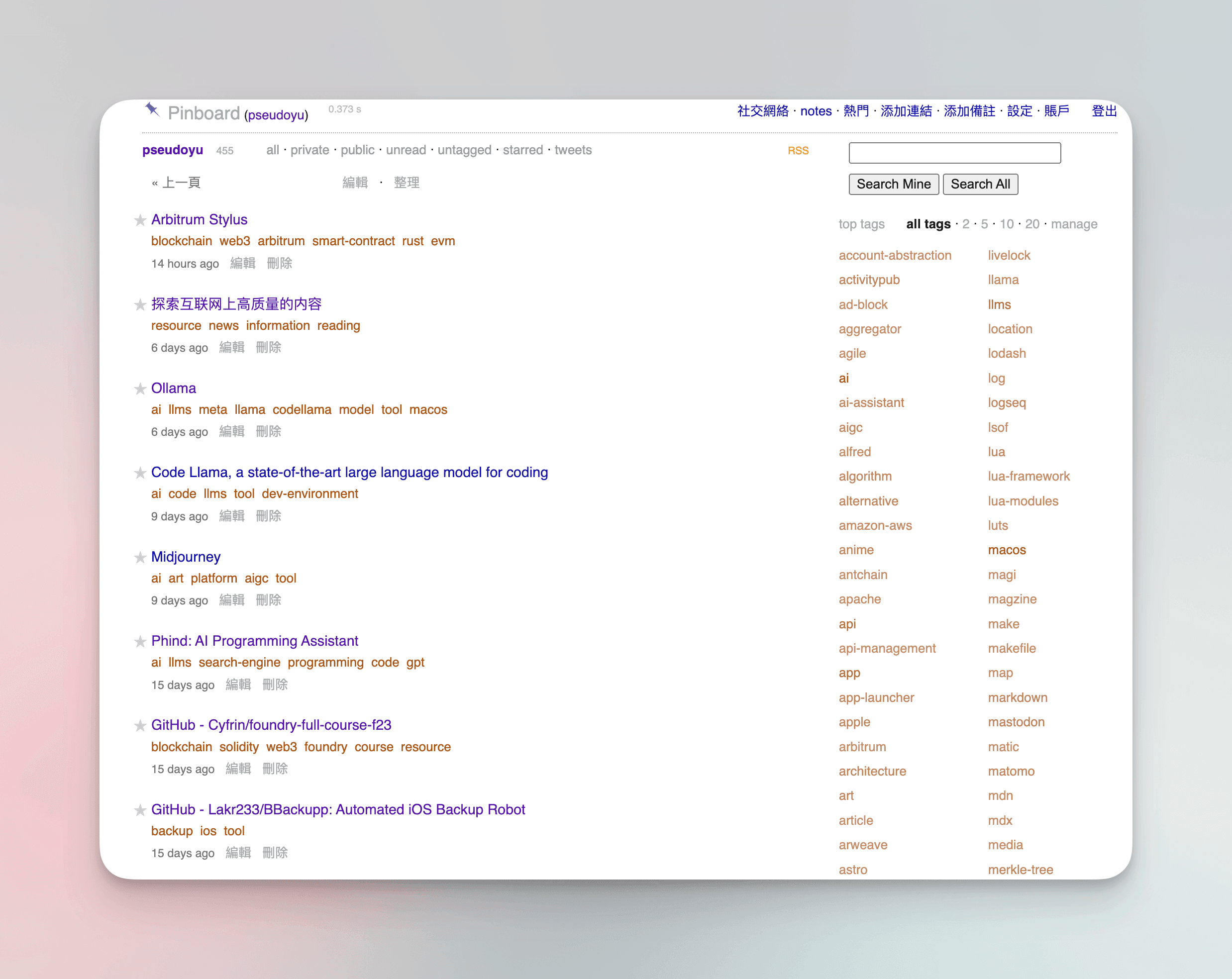
For useful websites, documents, code, software, or other resource-related information, I use pinboard, a classic yet very useful bookmark management tool. I save bookmarks using a browser extension, tagging them with simple descriptions. Over about a year, I have accumulated 455 bookmarks, most of which I can quickly retrieve through tags and names when needed.
For video sites, I mostly use likes or favorites to show support for creators and also sync them to my Telegram personal channel "Yu's Life" using some automation tools, tagging them accordingly. However, most video information is not very efficient, so they are mostly interesting or exploratory content.
Focused Reading#
In addition to the passive information streams mentioned above, we also have many specific themes or information needs closely related to our fields, which require us to actively read books, reports, etc.
I originally used Kindle or read physical books more, manually recording some notes in Logseq. However, after Randy launched the Notepal tool, I started using WeChat Reading, which has many readable book resources, and I also import some books in mobi or epub format into it, providing a good reading experience.

It is also very convenient for taking notes and highlighting. With cross-platform synchronization, I can easily sync to Readwise regularly through the Notepal browser extension, and the effect is great (the above image shows the synced content), which also motivates me to read books during fragmented time.
Information Management#
In the previous section, I outlined the channels and systems for information acquisition, but these are still scattered pieces of information. To make them part of my knowledge and thinking, I need more organization, digestion, and sedimentation. However, with so many platforms involved, searching and organizing is not convenient, and it is also challenging to establish connections between pieces of information. Inspired by the book "Building a Second Brain," I mainly did the following two things:
- Borrowed and adapted the P.A.R.A framework as my global tagging system.
- Used Logseq and Heptabase to build my Second Brain.
Global Tag System#

The P.A.R.A framework proposed by the author consists of:
- Projects: related to ongoing projects
- Areas: specific fields
- Resources: resources that may be used in the future
- Archives: completed projects
Based on these four types, I added a "Thoughts" category to classify my random thoughts.
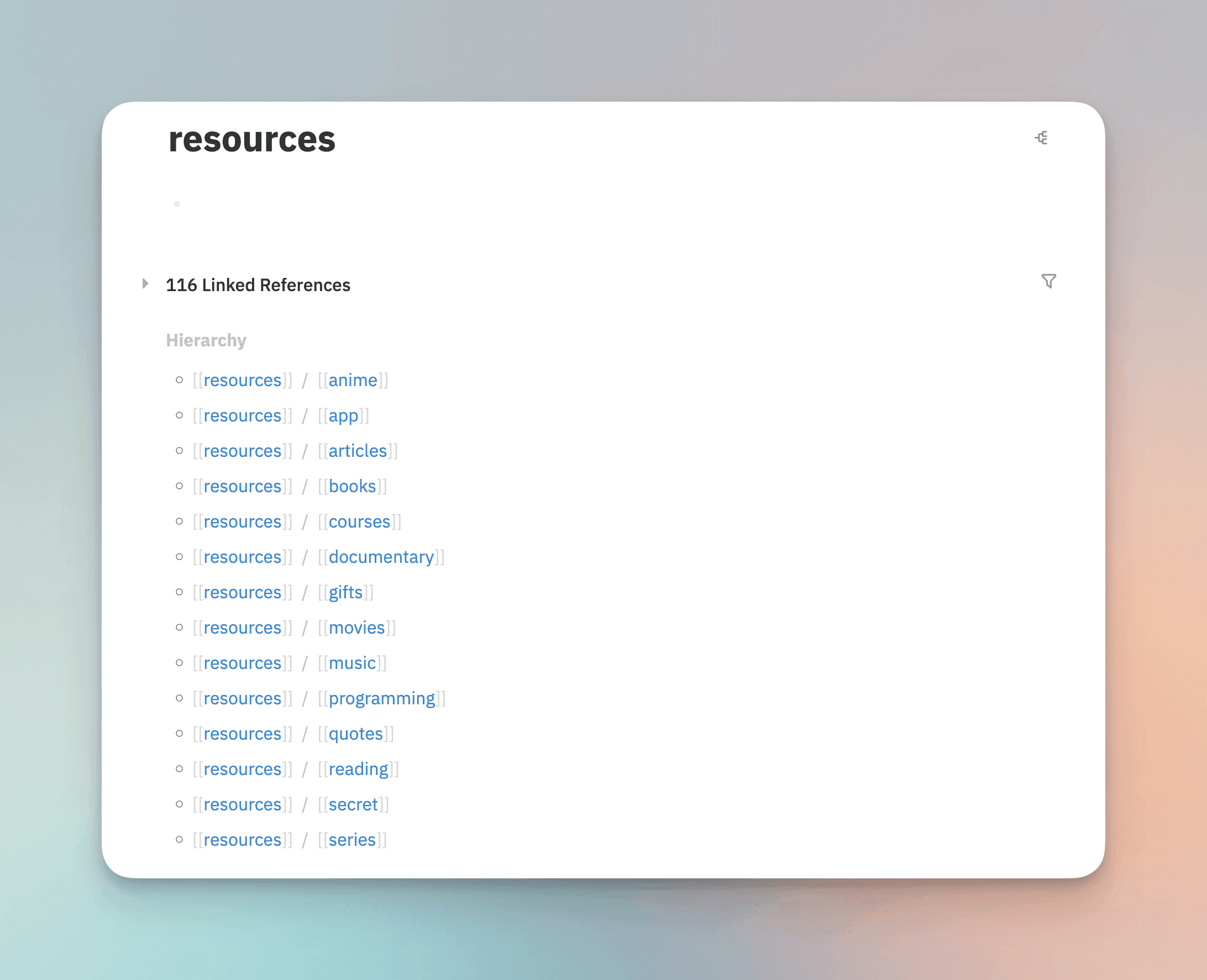
My implementation idea is to use these five types as my global primary tags, while more specific projects, fields, and industries can serve as secondary and tertiary tags, such as Projects/writing/pkm, Areas/blockchain, Thoughts/weekly-review, etc. Logseq provides a powerful multi-level tagging system that automatically layers based on /, making retrieval easy and classification clear. I modified some of my existing tags, and the effect is as follows:
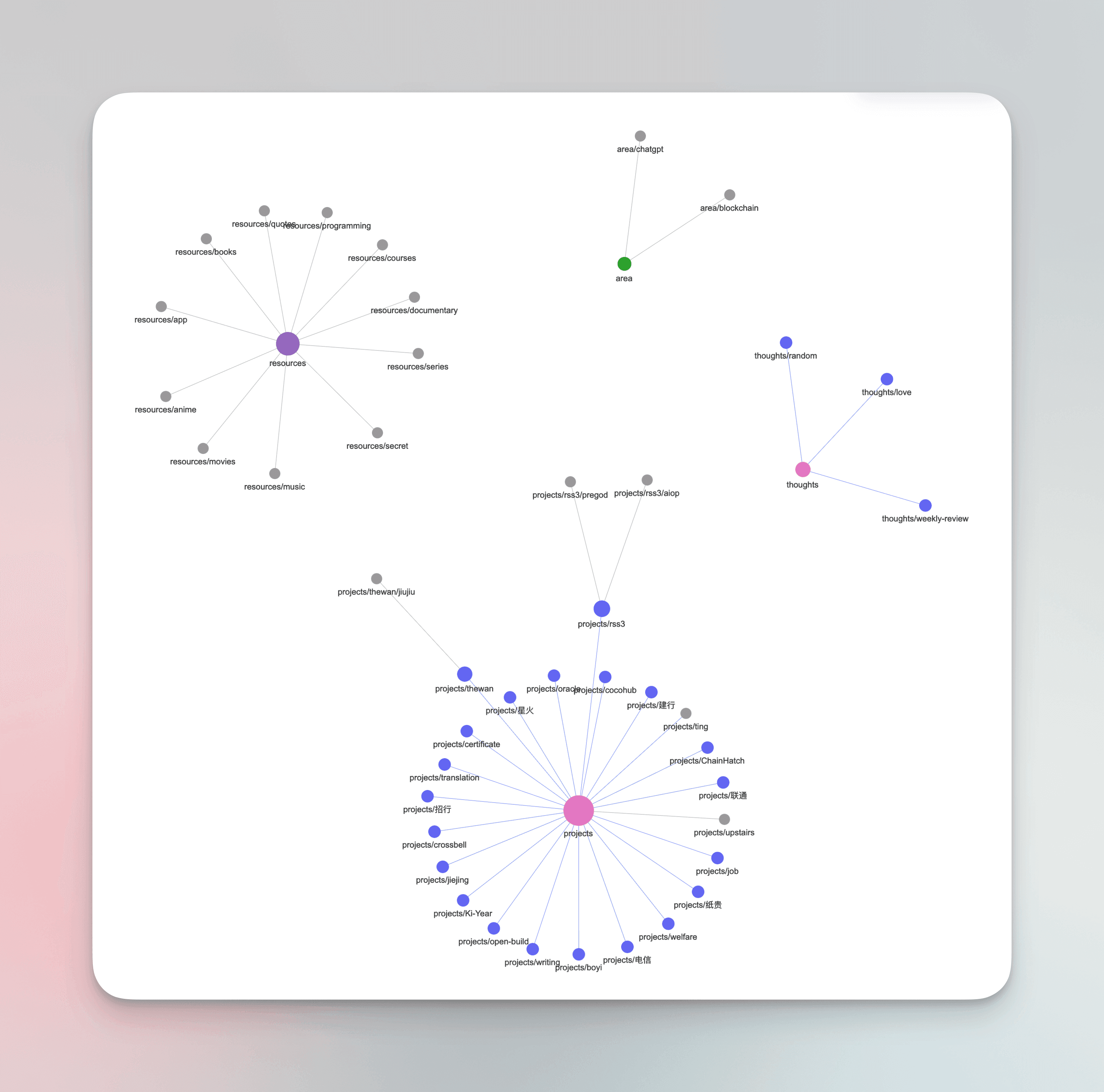
Second Brain Based on Heptabase + Logseq#
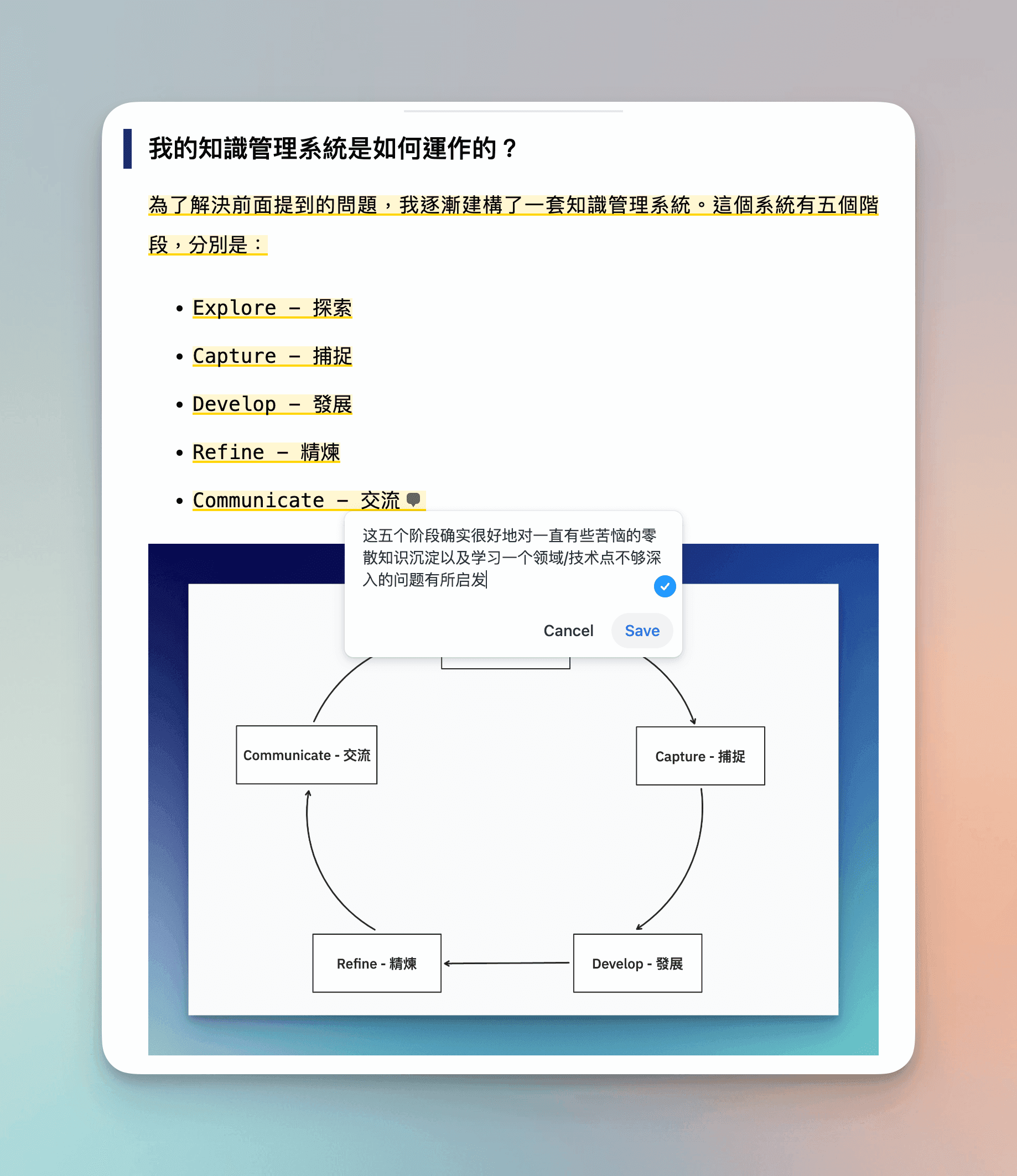
I have always used Logseq as my knowledge management system. Recently, after learning more about Heptabase through P.J. Wu 吳秉儒, I incorporated it into my knowledge management system, using both platforms in tandem to build my Second Brain. By following the tagging system mentioned above, the two platforms can perform their respective roles in information management without needing additional connections.

Logseq, as a note-taking system that combines simple task management and bidirectional linking, is very suitable for consolidating the information streams mentioned above and my initial thoughts after reading, such as highlights and comment notes. Since Logseq has an official Readwise plugin, it can easily sync my highlights and notes from WeChat Reading and online articles to Logseq pages, associating them with time and the Journal. This way, when I write reviews daily or weekly, I can intuitively see my past readings and thoughts. For example, the above image shows highlights and notes I made while reading "Everyone Only Has 24 Hours a Day, I Hope My Choices Are Truly My Choices" by MapleShadow Justin Yan, which were automatically synced to Logseq and tagged with some attributes based on my configuration.
Logseq is great for organizing and reviewing information, but when I need to research a specific field/concept, organize the context of books, or output a blog post, it feels a bit lacking. Its information is scattered in daily Journals as blocks, and while I can associate them through bidirectional links or tags, it is not convenient for direct visual connections. I also need to be clear about keywords and tags early on, which still carries some cognitive load. Therefore, I use Heptabase for management in this part.
Heptabase can be seen as a fully functional whiteboard note-taking tool. P.J. Wu 吳秉儒 has many high-quality introductory articles about Heptabase that you can read to learn more. In simple terms, it is divided into three levels:
- Map
- Whiteboard
- Card
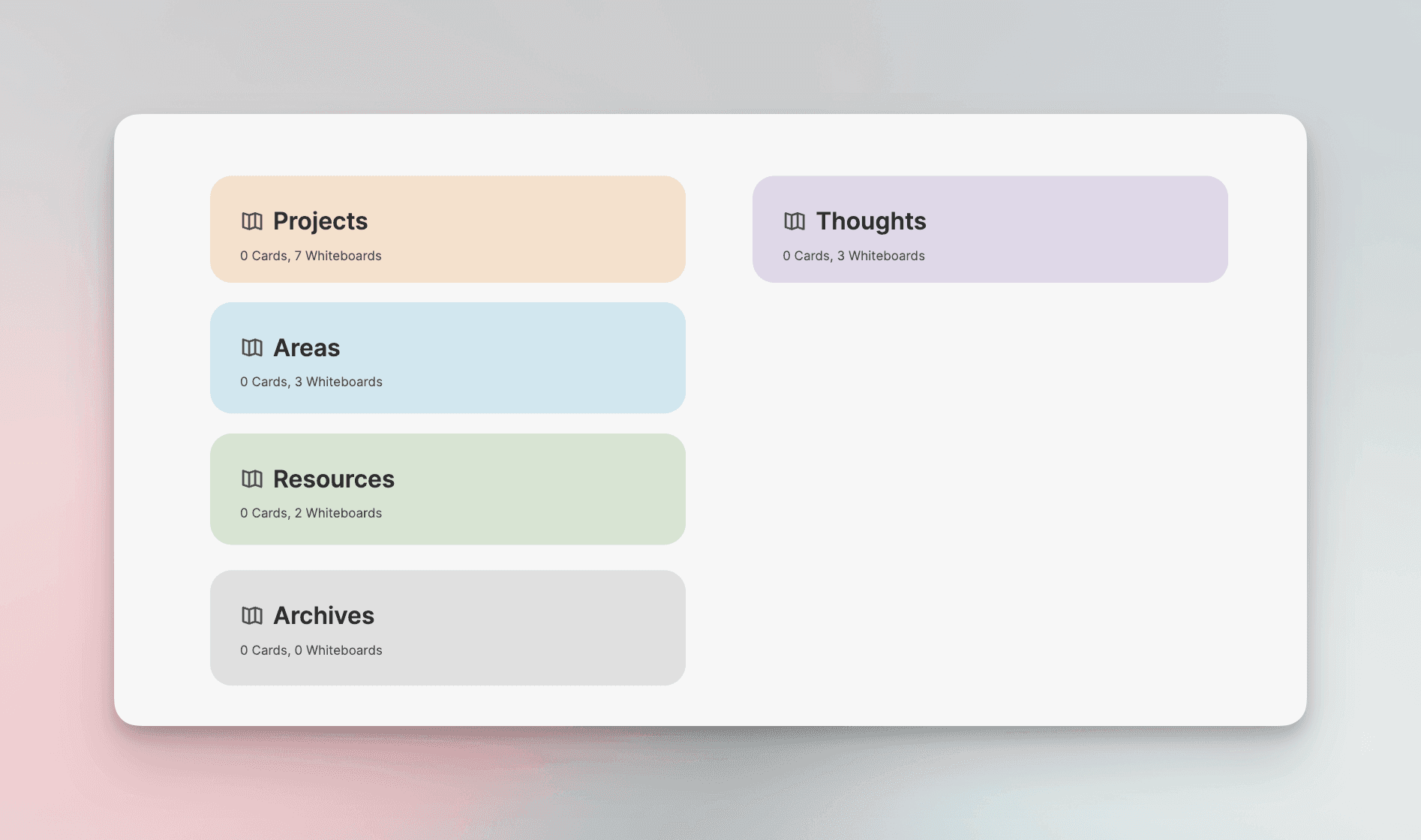
The Map can be viewed as the entire space of our Second Brain, containing various whiteboards. I have created five whiteboards to serve as the first-level tags.
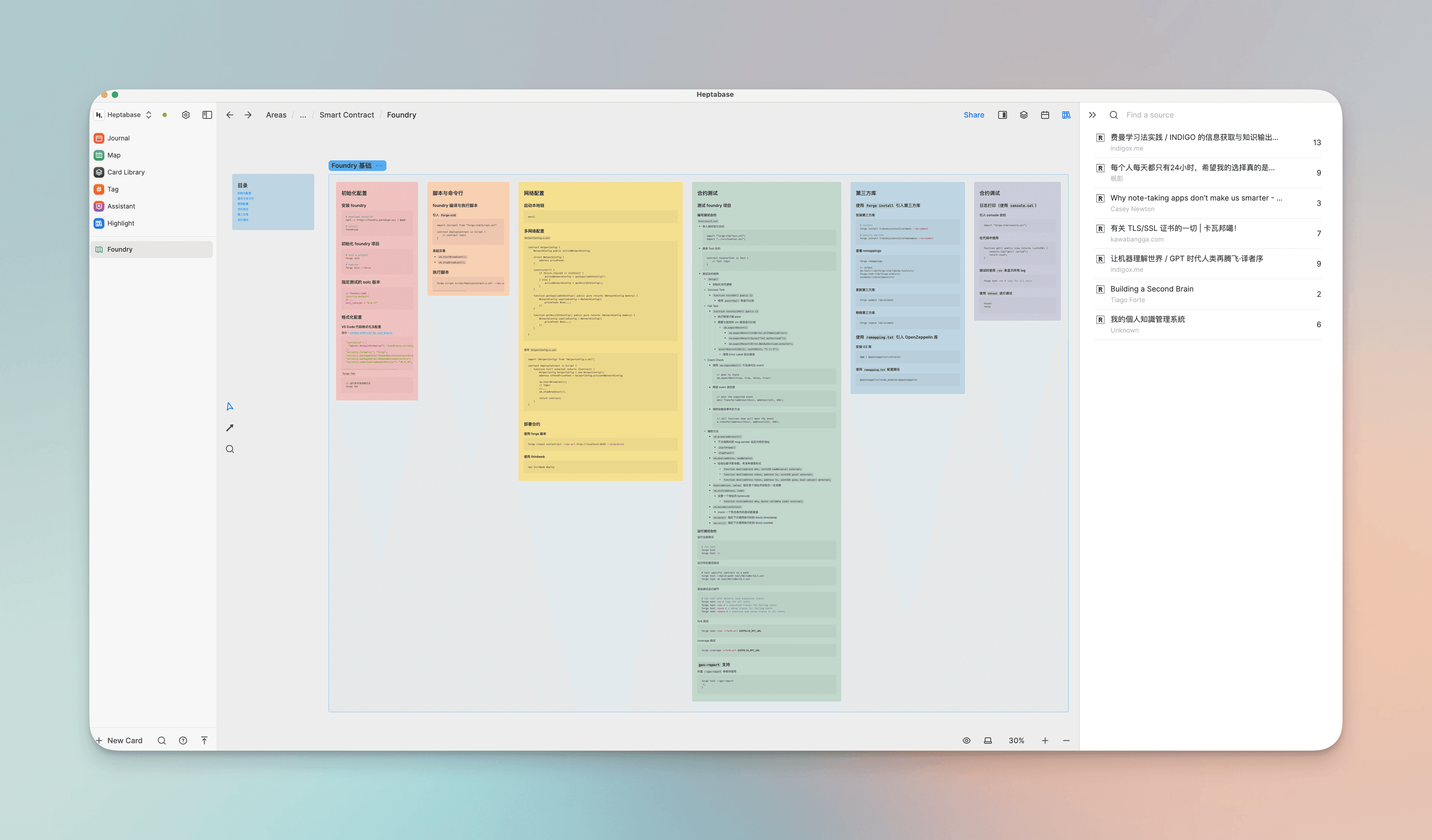
Cards represent individual ideas or independent information points in our minds. We can organize our knowledge through the associations between cards and the hierarchy between whiteboards and cards.
When I was writing a tutorial for the Foundry smart contract development framework, I first laid out some scattered knowledge points or experiences and lessons encountered in practice on the Foundry whiteboard (which is a fourth-level sub-whiteboard under Projects - Blockchain - Smart Contract). When a certain knowledge point accumulates enough, I group the whiteboards into sections and draw lines to associate them.
It also provides native integration with Readwise, allowing us to directly select highlights and notes from certain articles and books in Readwise as cards to bring into the whiteboard, establishing associations for them. This process resembles how our brains organize scattered information or brainstorm, perfectly meeting my needs.
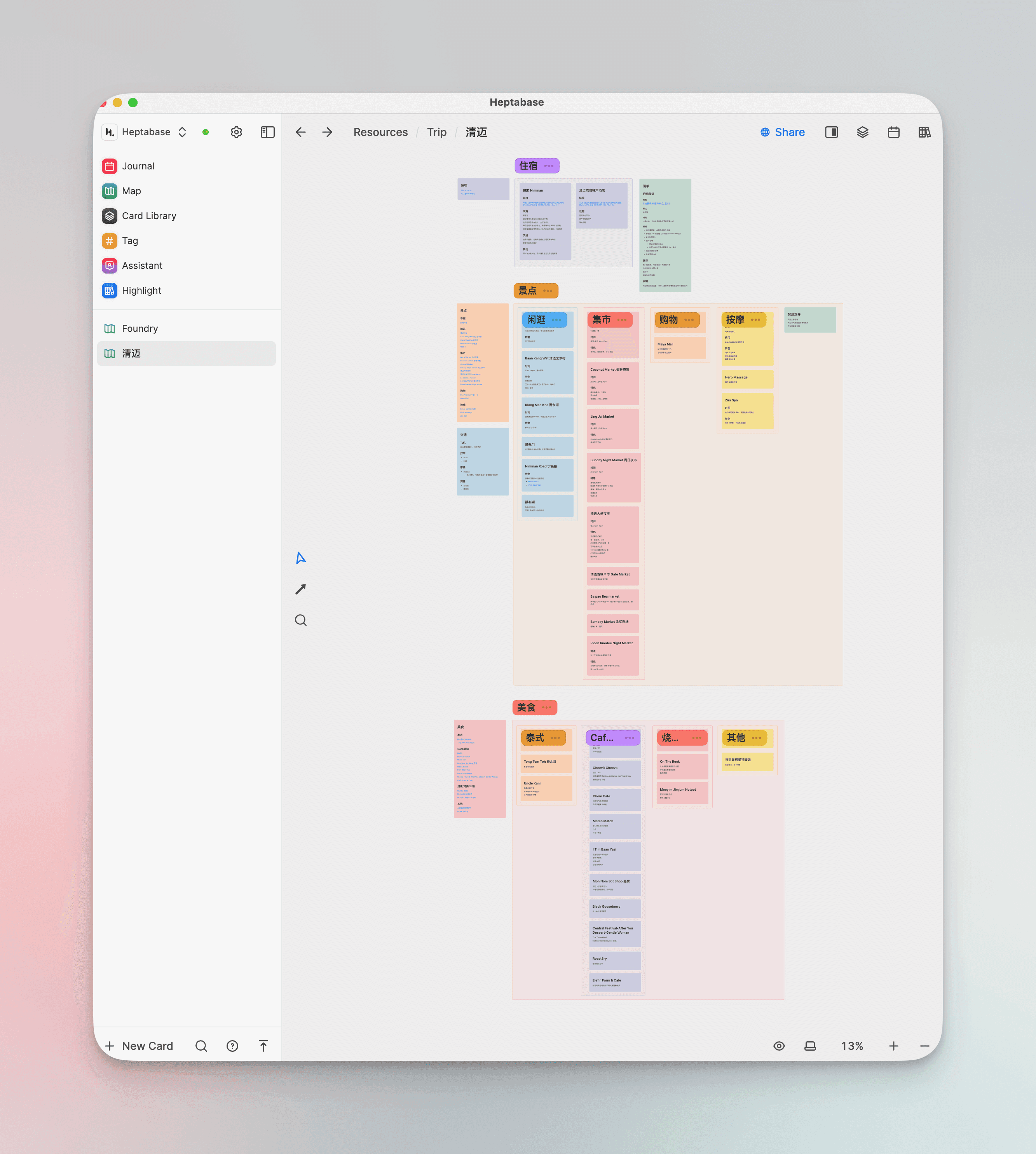
I currently also use it to create travel guides, placing information points from Xiaohongshu and other people's guide posts as individual cards on the travel planning whiteboard, and then organizing them through associations and groupings, making it very neat.
Information Output#
My output mainly consists of the following parts:
- Notes/Opinions/Daily
- Long Articles
- Thematic Research
- Information Stream
Notes/Opinions/Daily#
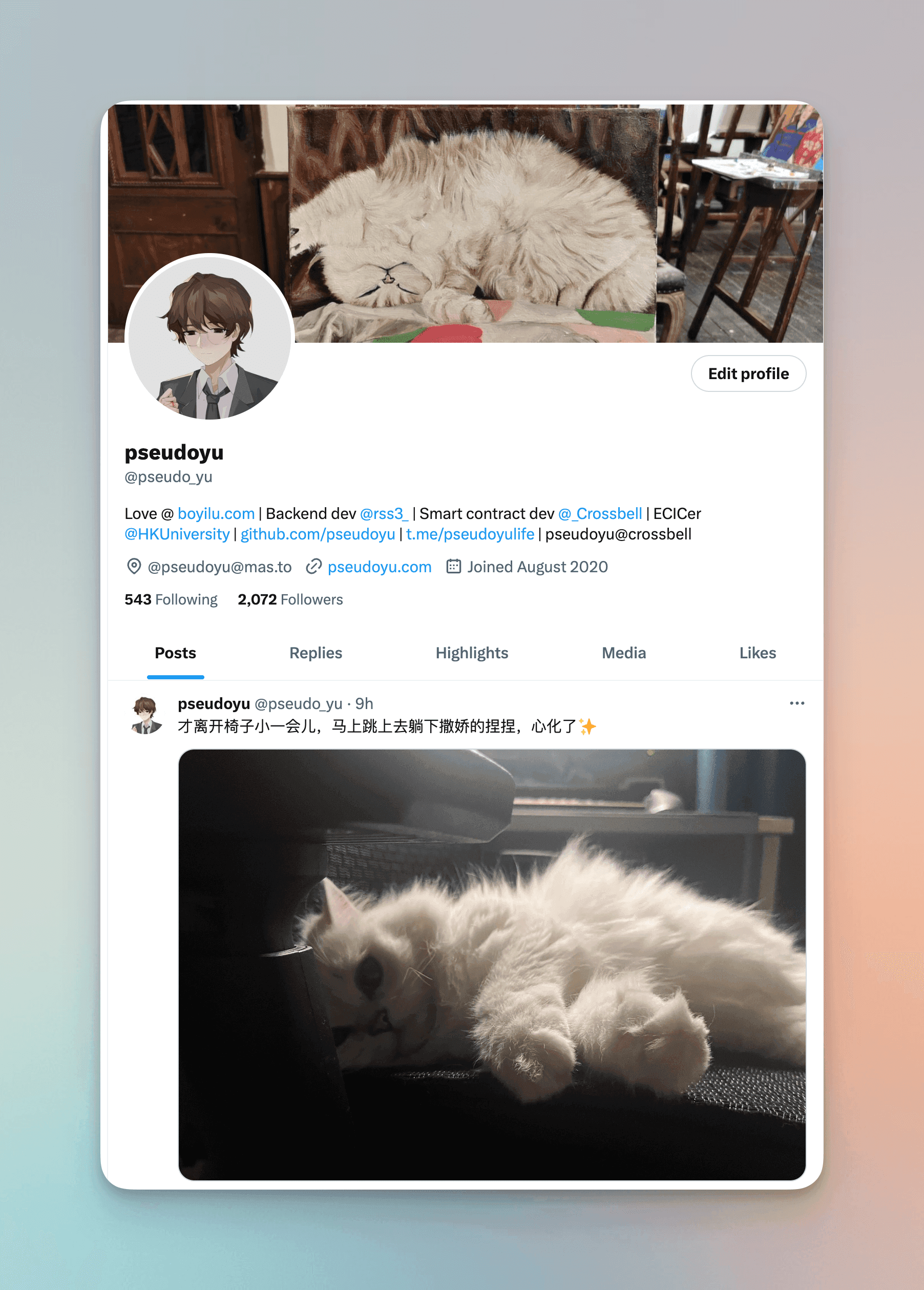
Among them, Twitter "pseudo_yu" is my primary unstructured information output channel. Sometimes it consists of thoughts on new technologies, feelings about work, emotions from meeting friends, or a cute cat picture, all contributing to my output and corresponding to the rapid production of those random thoughts in my input.
The friends I met on Twitter have also brought me a lot of warmth.
Long Articles#
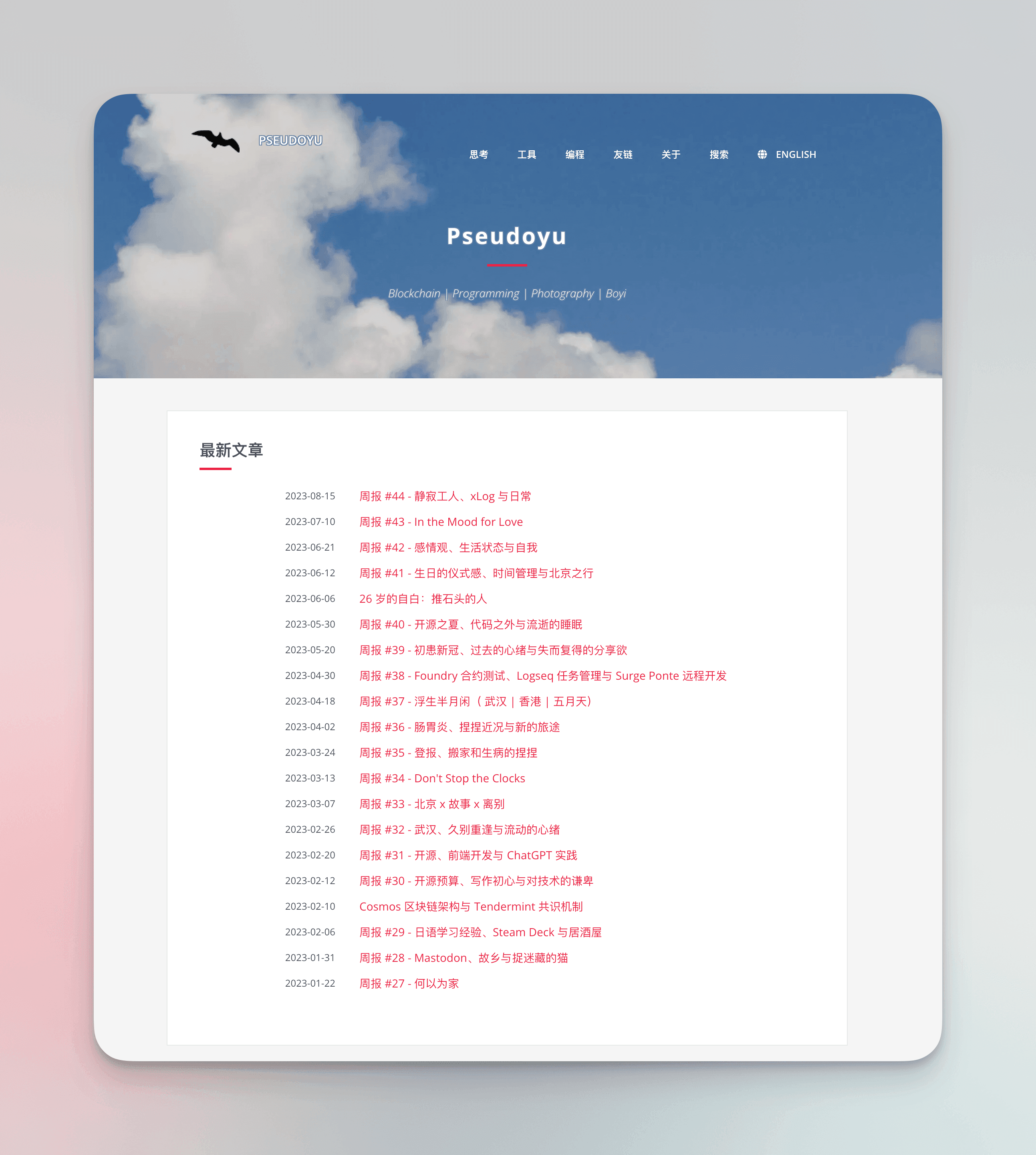
My most important output platform is my personal blog "Pseudoyu," where my weekly report is my main outlet, and occasionally I write thematic or specialized blog posts about technology or efficiency tools.
Thematic Research#
Outputting a blog post involves considering the audience, wording, and completeness, which carries a certain cognitive load and has a longer cycle. During my thematic research in specific fields, I mostly store learning materials and some demos in GitHub repositories or in a corner of a Logseq note. Sometimes, after a long time, I need to relearn. Now, I place more of this in a whiteboard in Heptabase, which can hold many small knowledge points and further summarize and refine them in subsequent creations. Thus, I can share this whiteboard after establishing a basic framework, facilitating communication with more people and helping friends who are also learning.
Information Stream Output#
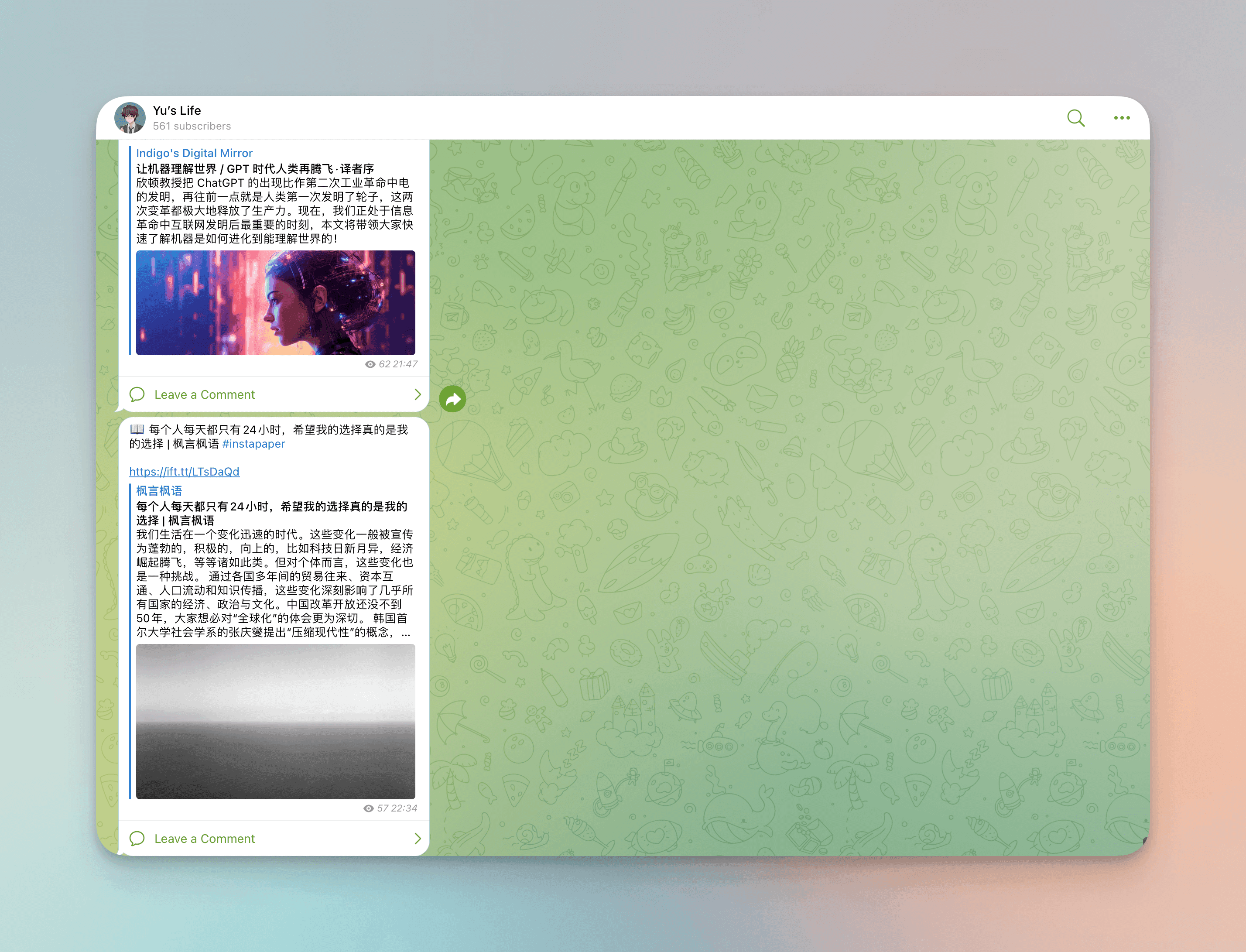
I have set up my own n8n synchronization service to collect my scattered information inputs and outputs across platforms. I also post my thoughts on movies and books, as well as other reflections, in my Telegram channel "Yu's Life." I follow some channels and groups to gather information or meet like-minded people, occasionally forwarding manually. I mainly sync the following platforms:
- Blog: now more like a life log.
- YouTube: I am also a heavy user, watching many technology-related tutorials and digital news, and occasionally some fun content.
- Bilibili: I mainly keep track of some creators I have followed for many years, watching travel vlogs more, only checking updates without looking at the homepage or trending content. I had previously planned to manage an account but currently have no good ideas.
- Pinboard: a bookmark and website management tool. I have saved many important contents in just a few months of use, heavily relying on it.
- Instapaper: managing "read later," mainly for saving quality or long articles.
- GitHub: also a daily check, looking at good projects and managing Stars with lists.
- Spotify: I mark good songs I hear on the above two music apps on Spotify.
- Douban: recording my books, shows, movies, anime, and games. I also use it heavily and am trying to write evaluations for every work I have seen or played.
Data Backup#
Although platforms like Twitter and Telegram are relatively large, they are still centralized products. Given the recent various upheavals, I am not at ease with collecting my information sources solely on Telegram, especially since I often almost delete everything when clearing messages (a strange interaction experience). Therefore, the synchronization and export of information is also a crucial part. I use xLog and xSync services under the Crossbell ecosystem for on-chain backups of my blog and information from various platforms.
xLog#
It has a good visual effect and user experience, and based on the Crossbell address, it allows for easy following and commenting. It includes features like an NFT showcase and personal portfolio. This is my xLog access address. Interested friends can follow it, but currently, due to considerations of customization, historical article migration routing issues, and changes in my various data statistics services, it serves more as a synchronization and distribution channel.
xSync#
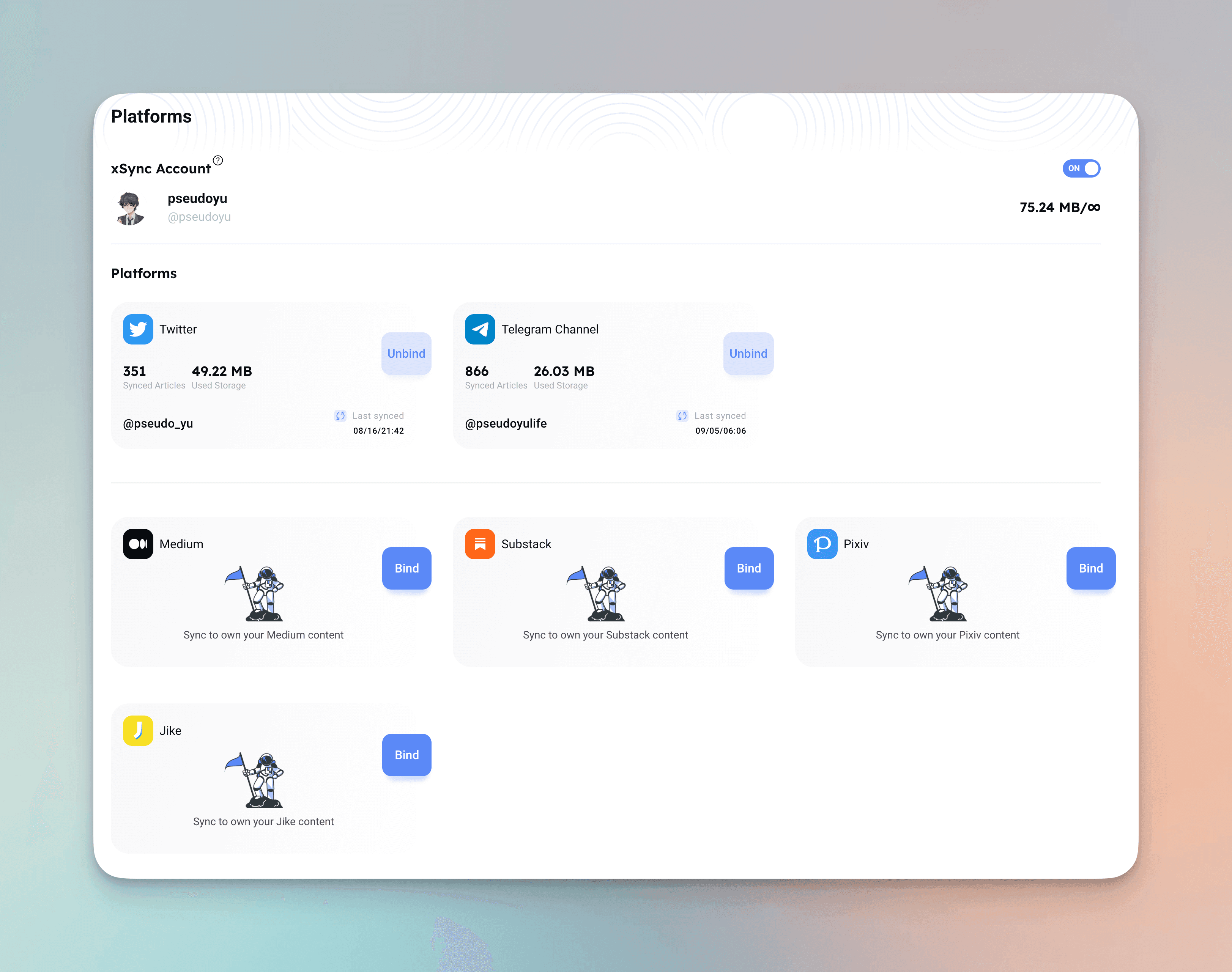
xSync can synchronize platforms like Twitter and Telegram Channels without requiring any intrusive modifications, allowing me to back up and archive my aggregation channel. Later, I can view my messages through xChar, which is a perfect solution. This is my xChar personal homepage: xChar, and you can also view my information stream through xFeed.
Conclusion#
it is probably a mistake, in the end, to ask software to improve our thinking.
Casey Newton said this in a recent article titled "Why note-taking apps don’t make us smarter." Indeed, these systems or software can only assist us in information management and output; they cannot replace our thinking. However, building a knowledge management system can not only please ourselves but also make our thinking more efficient. By pleasing ourselves, we can reach others, thus producing more valuable outputs.
I hope this article can be helpful to everyone.