Preface#
Databases are commonly used in both foundational knowledge learning and real enterprise business scenarios, and there are many jokes about how daily work is always related to CRUD. Proficiency in using mainstream relational databases is a fundamental skill for developers. This article will organize the basic knowledge and related operations of MySQL, a popular relational database, under the MacOS system for easy reference.
Overview of Data and Databases#
Data#
First, data is essentially a fact or an observed result, a logical summary of objective matters, and a form and carrier of information. People have been managing data for a long time (even before the concept existed), initially through manual management, and later gradually developing file systems (similar to libraries, categorizing different information). With the advancement of computer technology, a more convenient and efficient model of managing data through databases was finally formed.
Database#
A database is a repository that organizes, stores, and manages data according to a certain data structure, characterized by:
- Structured
- Shareable
- Low redundancy
- High independence
- Easy to expand
It is easy to understand that data organized according to different relationships/structures possesses different characteristics and is suitable for different application scenarios. Currently, databases are mainly divided into hierarchical databases, network databases, and relational databases, with MySQL being the relational database we will focus on.
Database Management System (DBMS)#
A Database Management System (DBMS) is a system for performing various operations on databases. It has core functions such as establishing and maintaining databases, organizing and managing data storage, controlling databases, defining data, manipulating data, and managing communication between data. Different DBMSs handle databases and data differently, and the presentation of data also varies. It is often necessary to choose an appropriate DBMS based on data scale, business needs, and other scenarios. For example, in cases of massive data and high-concurrency data read/write, the performance of relational databases can significantly decline.
Relational Database (RDBMS)#
Main Features#
Relational databases mainly present data in the form of tables, where each row is a record and each column corresponds to a data field of the record. Many rows and columns make up a single table, and several single tables constitute a database. Users/systems query the database using SQL (Structured Query Language).
Some operations in relational databases have transactional properties, namely the ACID rules:
- Atomicity
- Consistency
- Isolation
- Durability
Atomicity means that a series of transactional operations must either all complete or all fail; there cannot be a situation where only part of the operations are completed. For example, in a bank transfer scenario, after the transfer occurs, the sender's balance decreases, and if there is an operational error in the database causing the receiver's balance not to increase, it would lead to serious issues.
Consistency means that after a transaction is completed, the data in the entire database should be consistent, and there should be no situation where the same data is out of sync within the database.
Isolation means that different transactions should run independently and not interfere with each other. Of course, this sacrifices some efficiency but provides better guarantees for data accuracy.
Durability means that once a transaction is completed, the changes it made to the database and its effects on the system are permanent.
Data Integrity#
Data integrity is a crucial requirement and attribute of databases, meaning that the data stored in the database should maintain consistency and reliability, mainly divided into the following four types:
- Entity integrity
- Domain integrity
- Referential integrity
- User-defined integrity
Entity integrity requires that each data table has a unique identifier, and the primary key field in each table cannot be null or duplicated, which mainly means that the data in the table can be uniquely distinguished.
Domain integrity involves imposing additional restrictions on the columns in the table, such as limiting data types, checking constraints, setting default values, allowing null values, and defining value ranges.
--- Enforcing uniqueness on fields when creating a table
create table person (
id int not null auto_increment primary key,
name varchar(30),
id_number varchar(18) unique
);
Referential integrity means that the database does not allow references to non-existent entities. There are often associations between tables in the database and other tables, which can be ensured through foreign key constraints.
User-defined integrity involves imposing some semantic restrictions on the data based on specific application scenarios and the data involved, such as ensuring that balances cannot be negative, typically enforced through rules, stored procedures, and triggers.
Mainstream RDBMS#
Currently, the mainstream relational databases include the following:
- SQL Server
- Sybase
- DB2
- Oracle
- MySQL
Oracle and MySQL are the two most commonly used by enterprises and individuals, and the following sections will provide detailed operational explanations using MySQL as an example.
MySQL#
Installation and Startup#
MySQL is a popular small database system developed and maintained by Sun Microsystems (later acquired by Oracle). Due to its small size and fast data processing, it is adopted by many small and medium-sized enterprises/websites and has a relatively complete development and maintenance ecosystem.
As a personal user, you can download the community version (open source) to set up a local environment. You can choose different versions based on different systems and also have a convenient graphical interface for starting, stopping, restarting the service, and making related configurations. This article uses MySQL 8.0.21 under the MacOS system as an example. After installation and basic setup, you can manage the local MySQL service. The version may vary slightly, but the core functionality remains largely the same.
Graphical Interface#
Open System Preferences, and you will see the following interface:
Clicking the MySQL icon will take you to the detailed management interface:
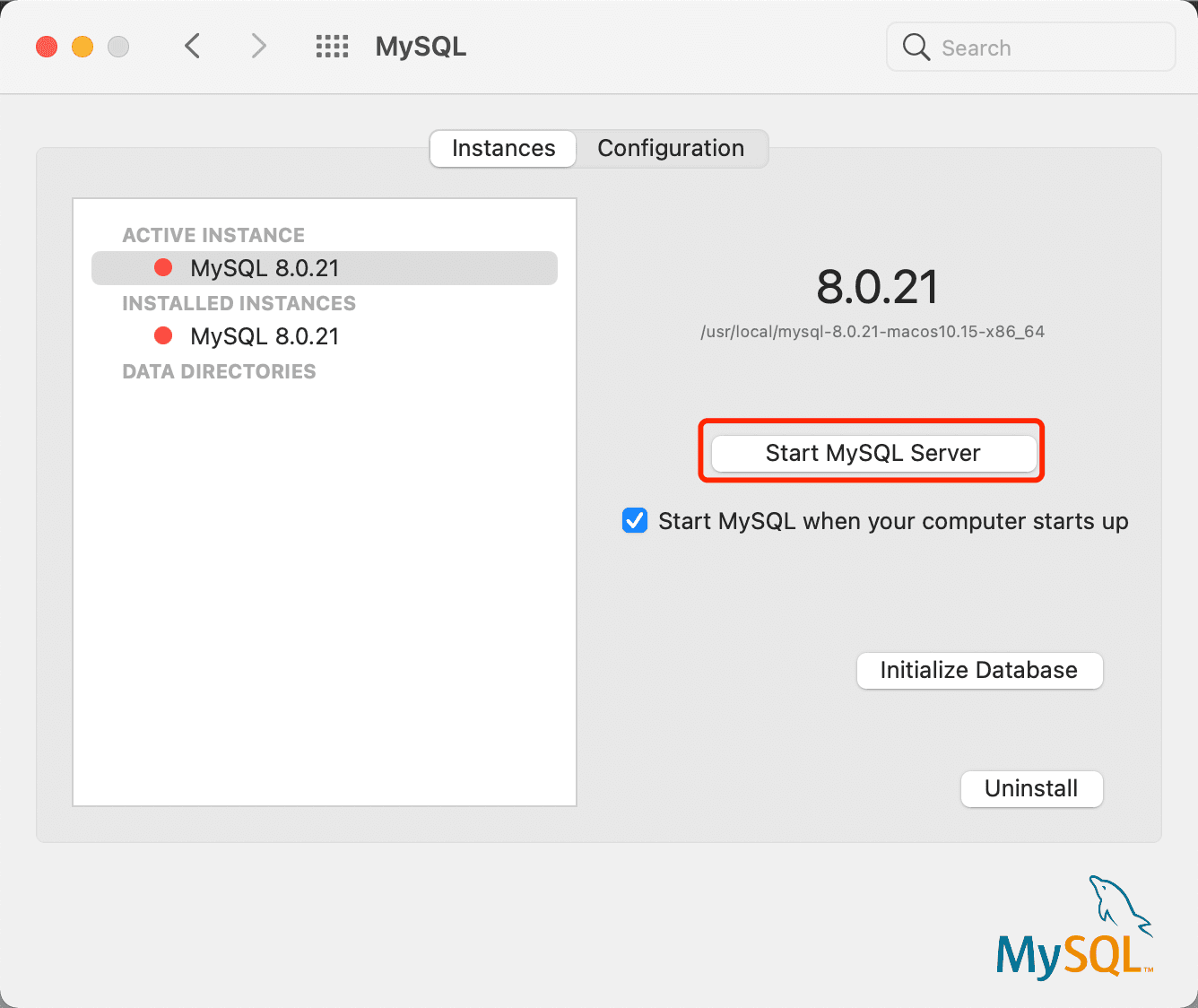
In this management interface, you can easily start and stop the MySQL service, and you can also set it to start automatically at boot. Further settings can be made in Configuration, but it is recommended to use the command line for more advanced configurations.
Command Line Interface#
Of course, you can also start MySQL from the command line:
// Start MySQL
sudo /usr/local/mysql/support-files/mysql.server start
// Stop MySQL
sudo /usr/local/mysql/support-files/mysql.server stop
The result is as follows:

You can also set some aliases to simplify commands, but since there is a convenient management interface, it may not be necessary. If you are operating in a Linux environment without a graphical interface, command line operations will be required.
Connecting to MySQL#
After installation and startup, you can connect to MySQL via the command line and perform some basic operations:
mysql -h localhost -u root -p
// Enter the password set during installation
// Check status
status;

In addition to connecting via the command line, there is also a very useful client on the MacOS platform called Sequel Pro, which provides most of the necessary features. Since the official version has stability issues and is no longer maintained, it is recommended to download the test version Sequel Pro Test Build, which can easily connect to local/remote MySQL services.
You can query the structure and content of the database and execute SQL commands:
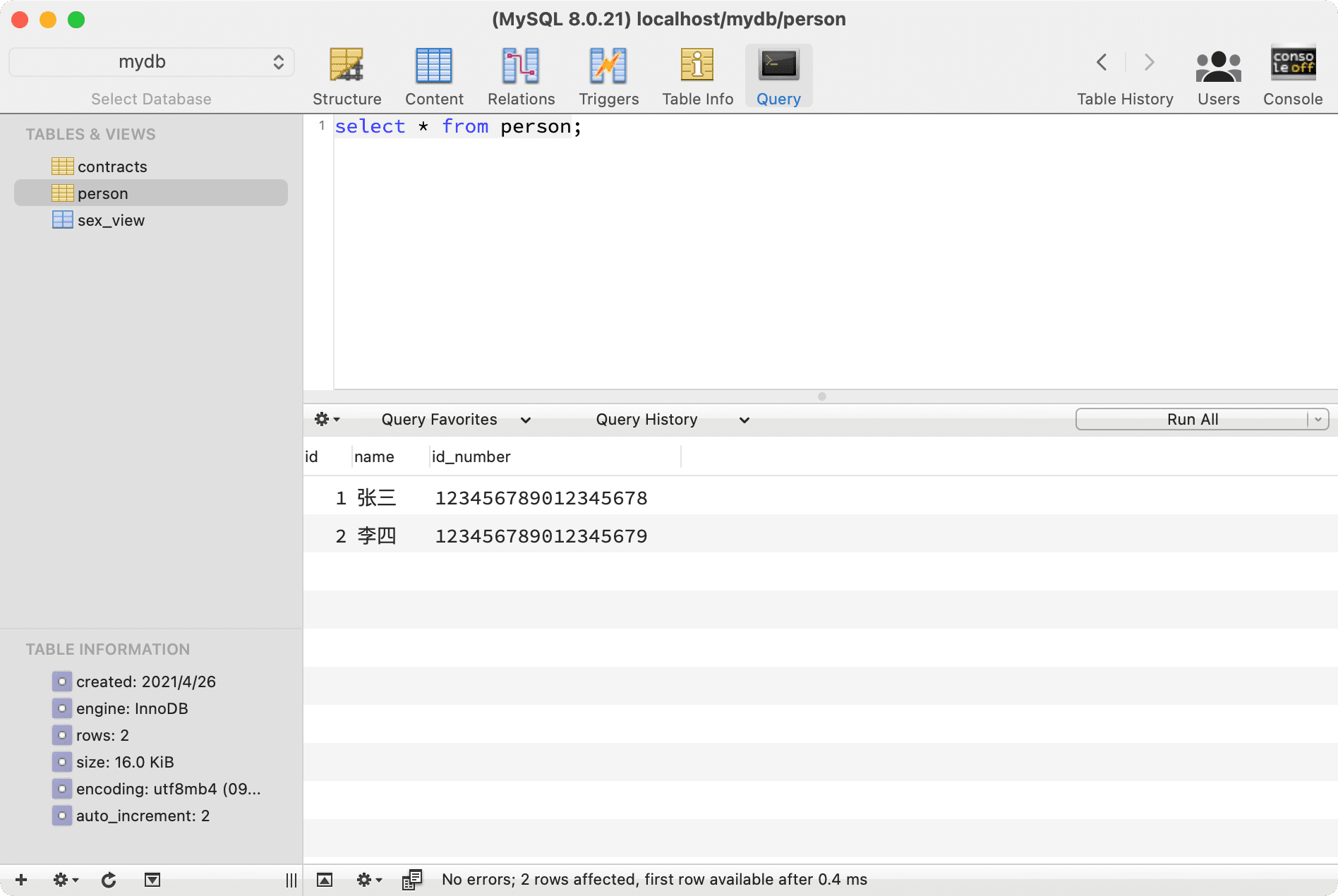
This is a very powerful and lightweight client that I highly recommend!
SQL Commands#
After configuring and connecting to MySQL locally, we can perform some operations on the database. SQL language is mainly divided into the following four categories:
- DDL Data Definition Language
- DML Data Manipulation Language
- DQL Data Query Language
- DCL Data Control Language
Next, we will complete a series of operations through practical examples.
DDL Operations#
--- Create a database
create database learn_test;
--- Show all databases
show databases;
--- Drop a database
drop database mydb;
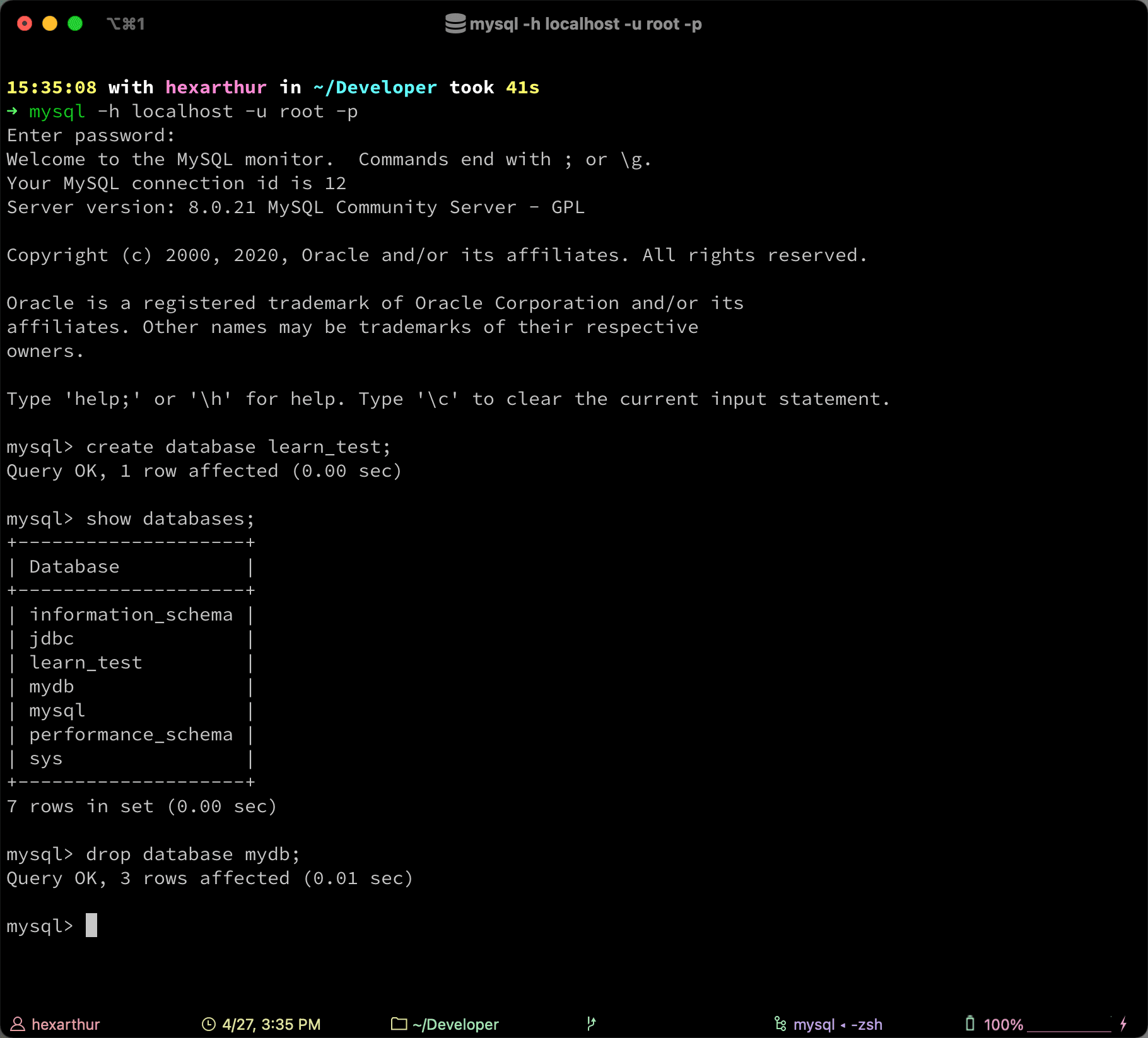
--- Enter a specific database
use learn_test;
--- Create a simple data table
create table contacts (
id int not null auto_increment primary key,
name varchar(30),
phone varchar(20)
);
--- Add a field
alter table contacts add sex varchar(1);
--- Modify a field
alter table contacts modify sex tinyint;
--- Drop a field
alter table contacts drop column sex;
--- Drop the entire table
drop table contacts;
For demonstration purposes, these operations will be performed in the Sequel Pro client, and after the operations, our table structure will look like this:
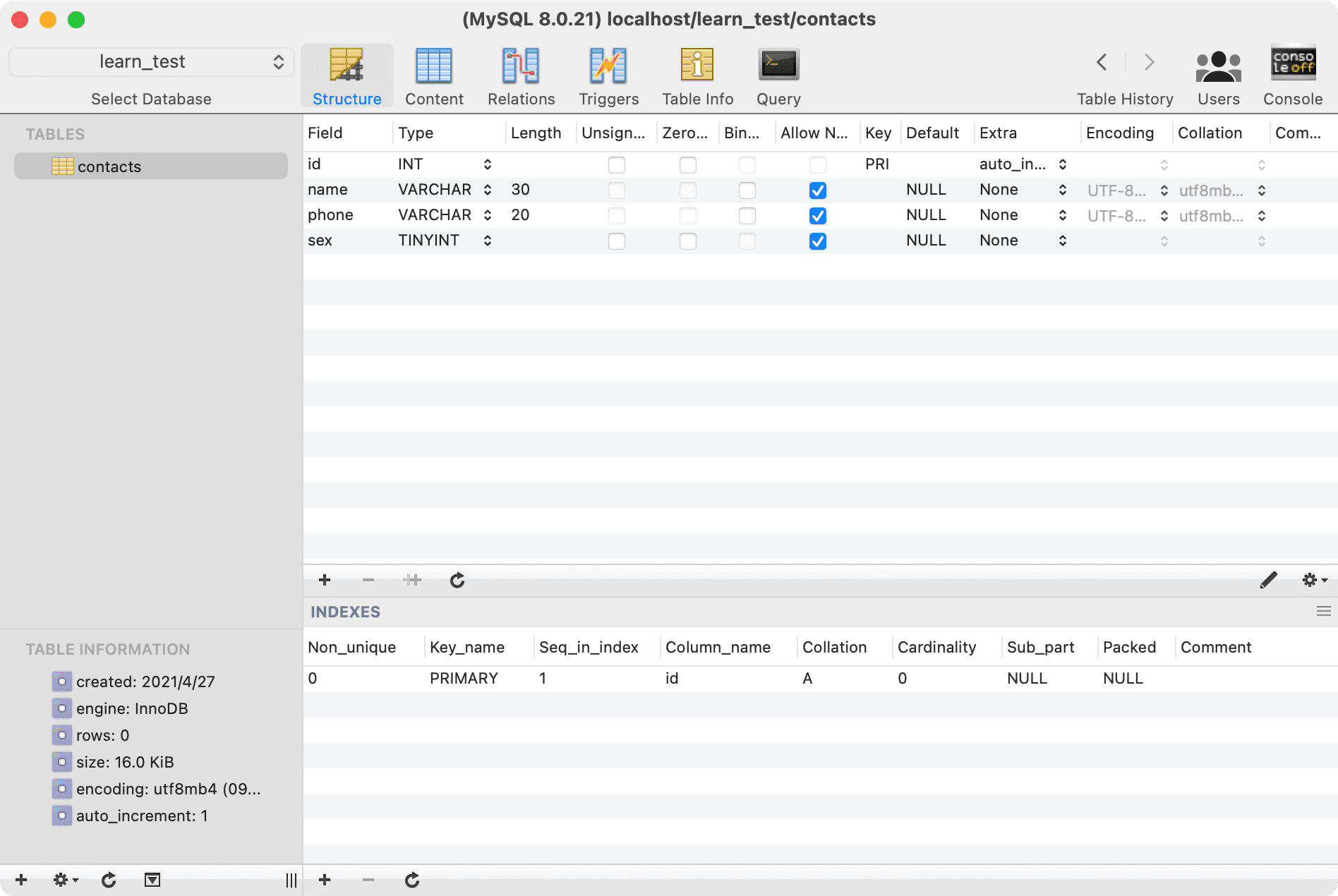
DML Operations#
--- Insert multiple records
insert into contacts (name, phone, sex) values('Zhang San', '13100000000', 1), ('Li Si', '13100000001', 1), ('Wang Wu', '13100000002', 2);
--- Update data content
update contacts set sex = 1 where name = 'Wang Wu';
--- Delete data content
delete from contacts where id = 3;
DQL Operations#
MySQL can query tables using the select command, with the most commonly used command to view all data being:
--- View all data in the table
select * from contacts;
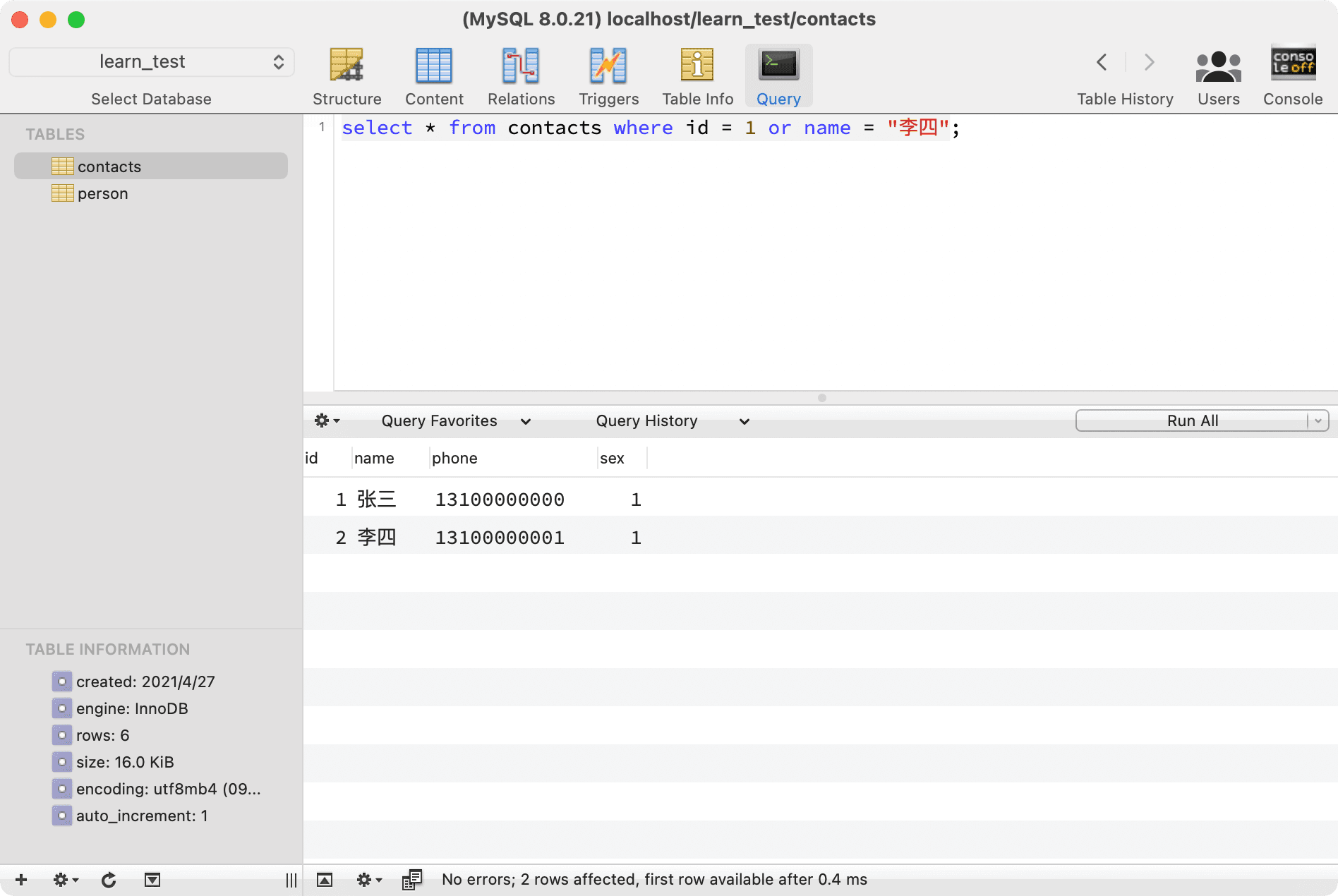
You can also use the where keyword for conditional queries and combine multiple conditions:
--- Combine conditions for querying
select * from contacts where id = 1 or name = "Li Si";
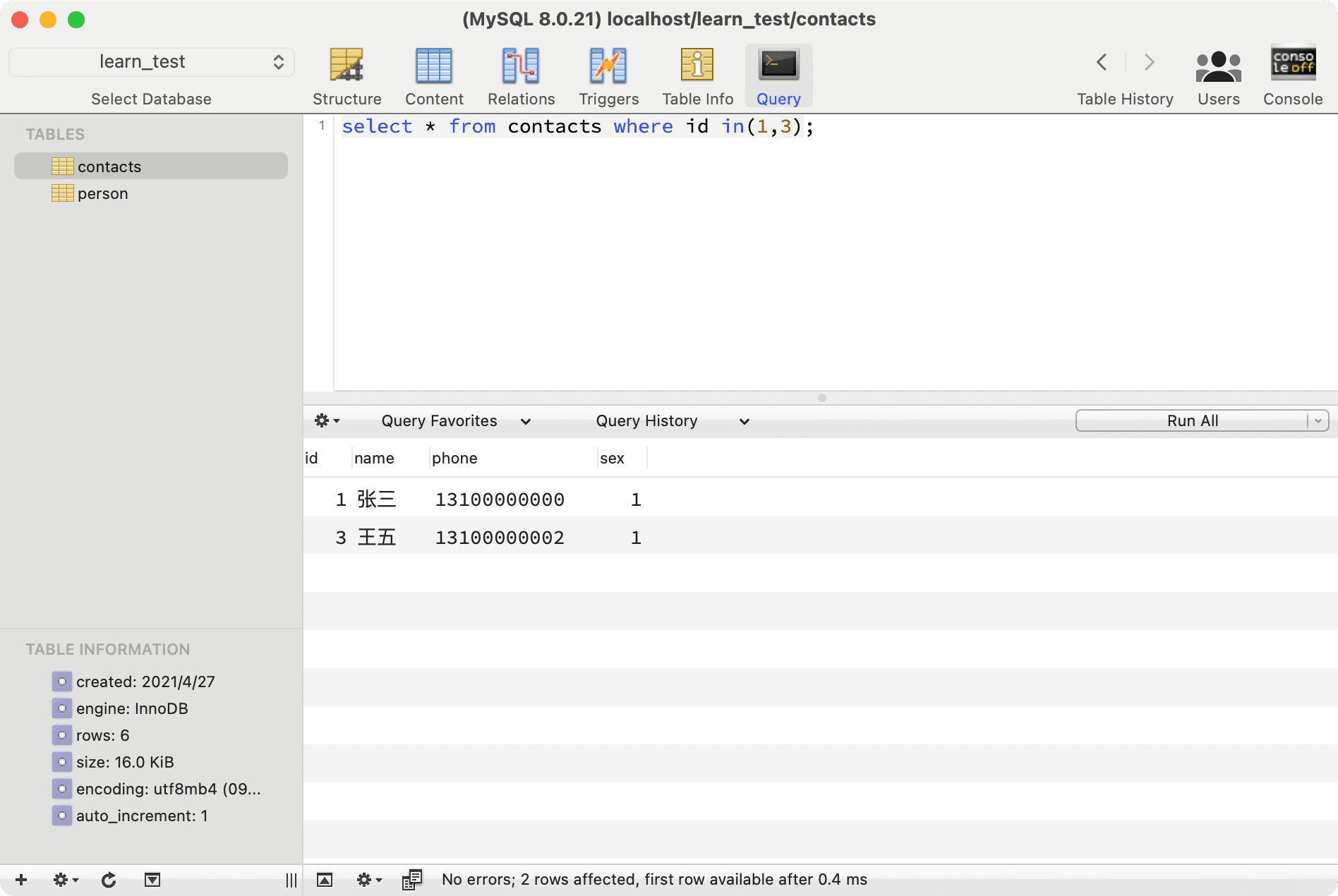
IN and LIKE are also two keywords that can be flexibly used for queries.
IN helps filter multiple values for a specific field:
--- Query data where id is in (1,3)
select * from contacts where id in(1,3);
Additionally, IN and EXISTS can be used for subqueries:
--- Subquery IN
select A.*
from student A
where A.stu_no in(
select B.stu_no from score B
);
--- Subquery EXISTS
select A.*
from student A
where exists(
select * from score B
where A.stu_no = B.stu_no
);
LIKE can help perform fuzzy searches based on inclusion relationships, where % can match any character and _ can match a single character:
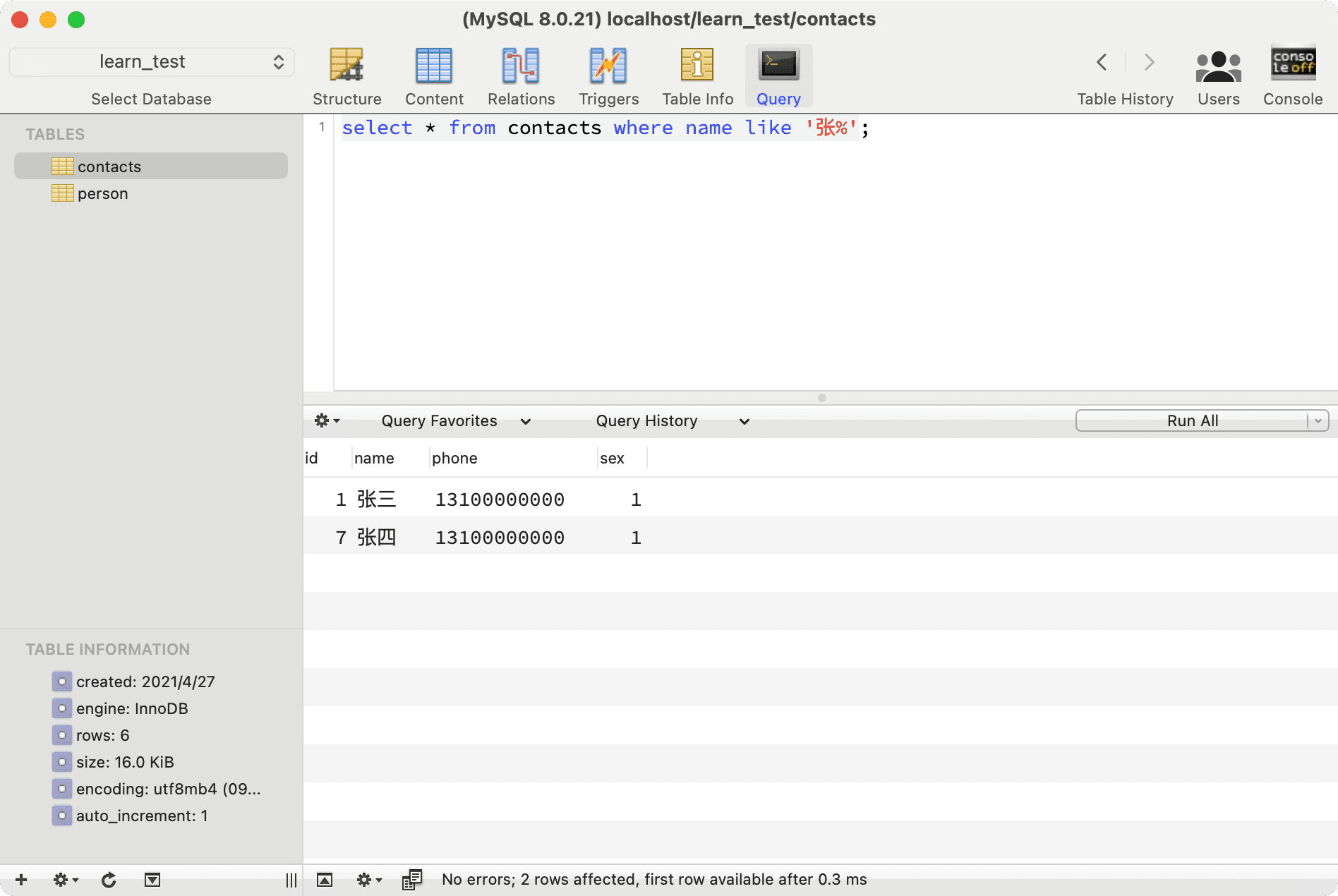
--- Query all contacts with the surname Zhang
select * from contacts where name like 'Zhang%';
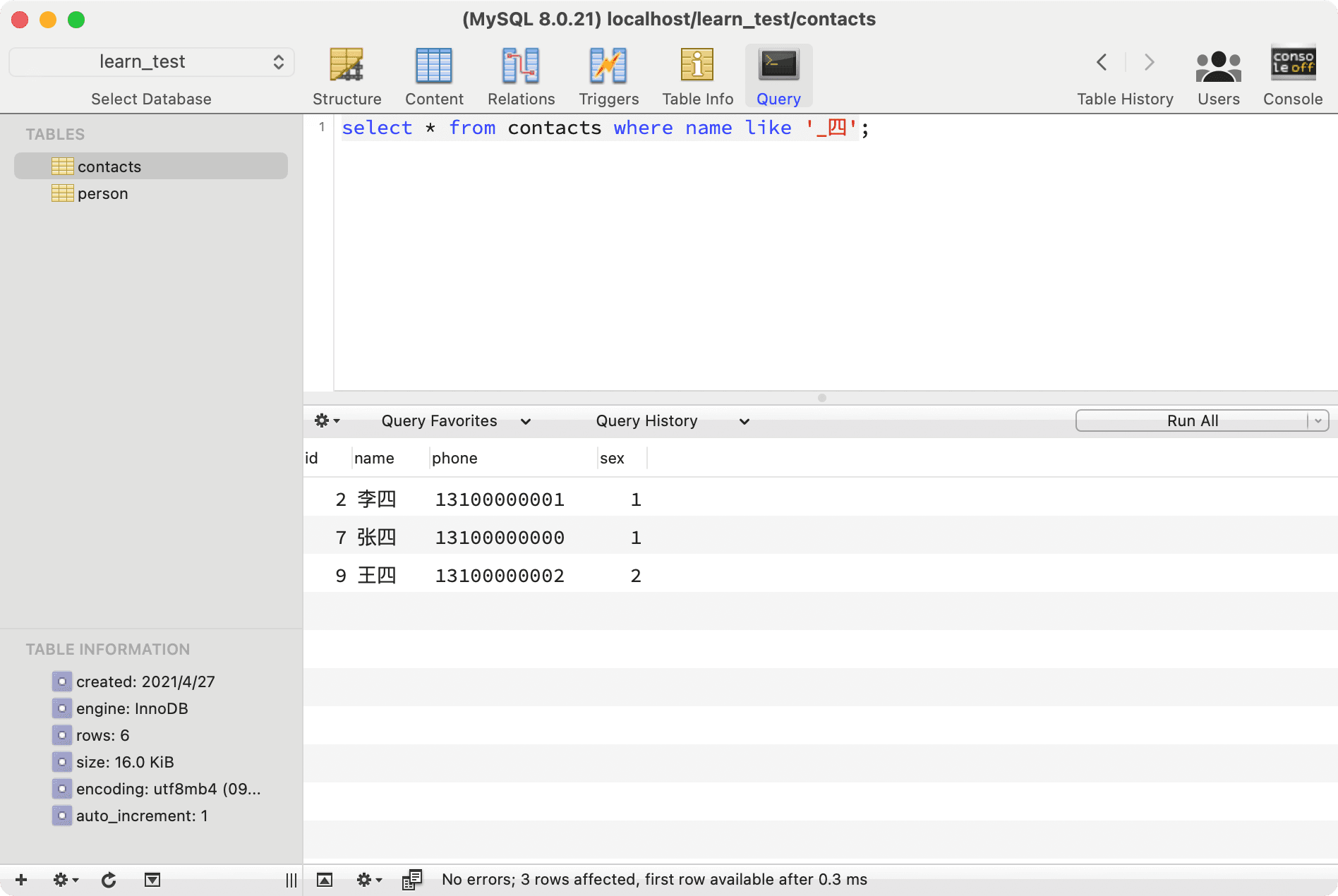
--- Query all contacts whose names end with Si and consist of two characters
select * from contacts where name like '_Si';
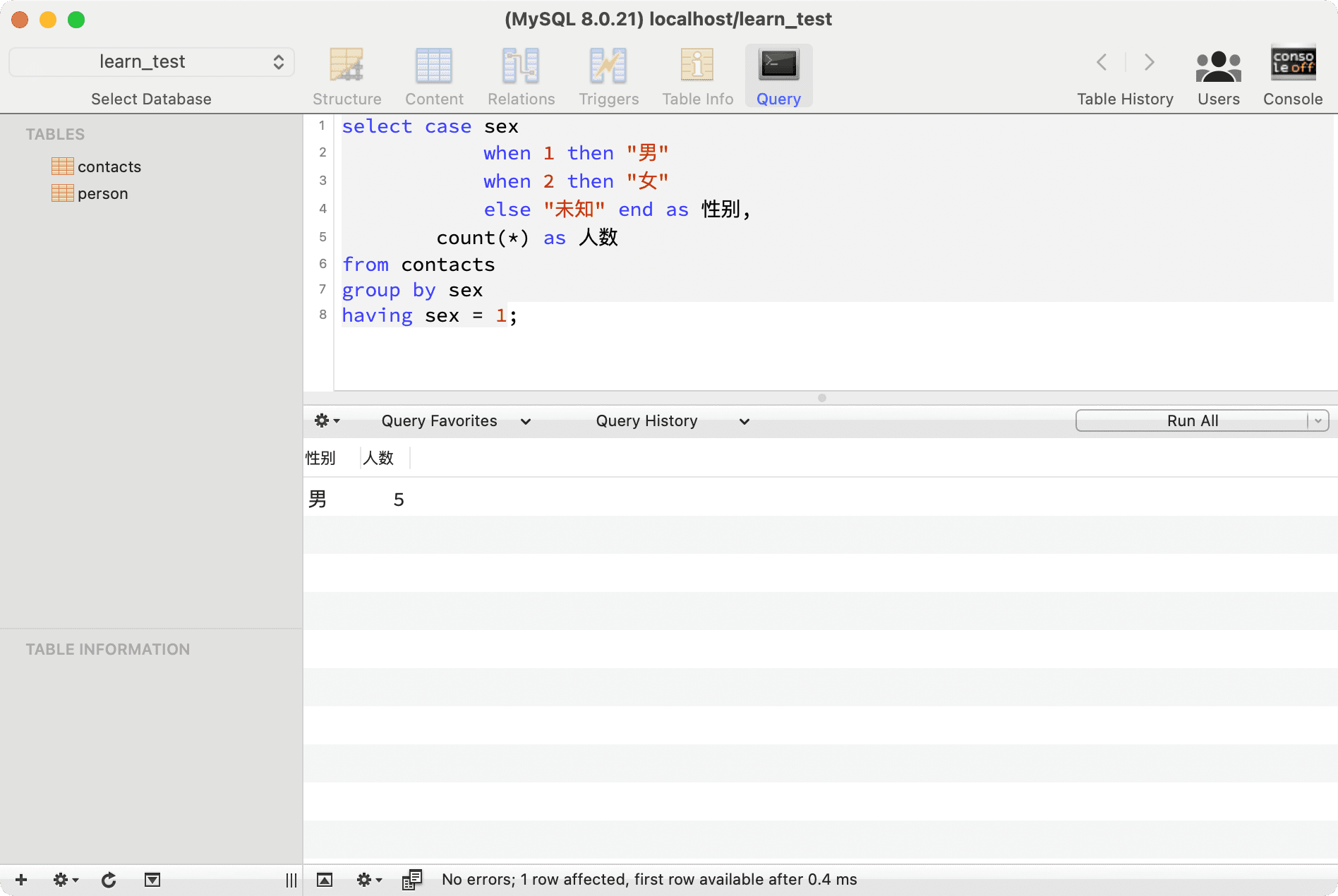
In practical applications, data tables often contain a large volume of data, and data may need to be grouped based on certain conditions, which requires the use of the GROUP BY keyword, along with HAVING for further filtering conditions. GROUP BY needs to be used in conjunction with aggregate functions.
--- Count the number of male contacts
select case sex
when 1 then "Male"
when 2 then "Female"
else "Unknown" end as Gender,
count(*) as Count
from contacts
group by sex
having sex = 1;
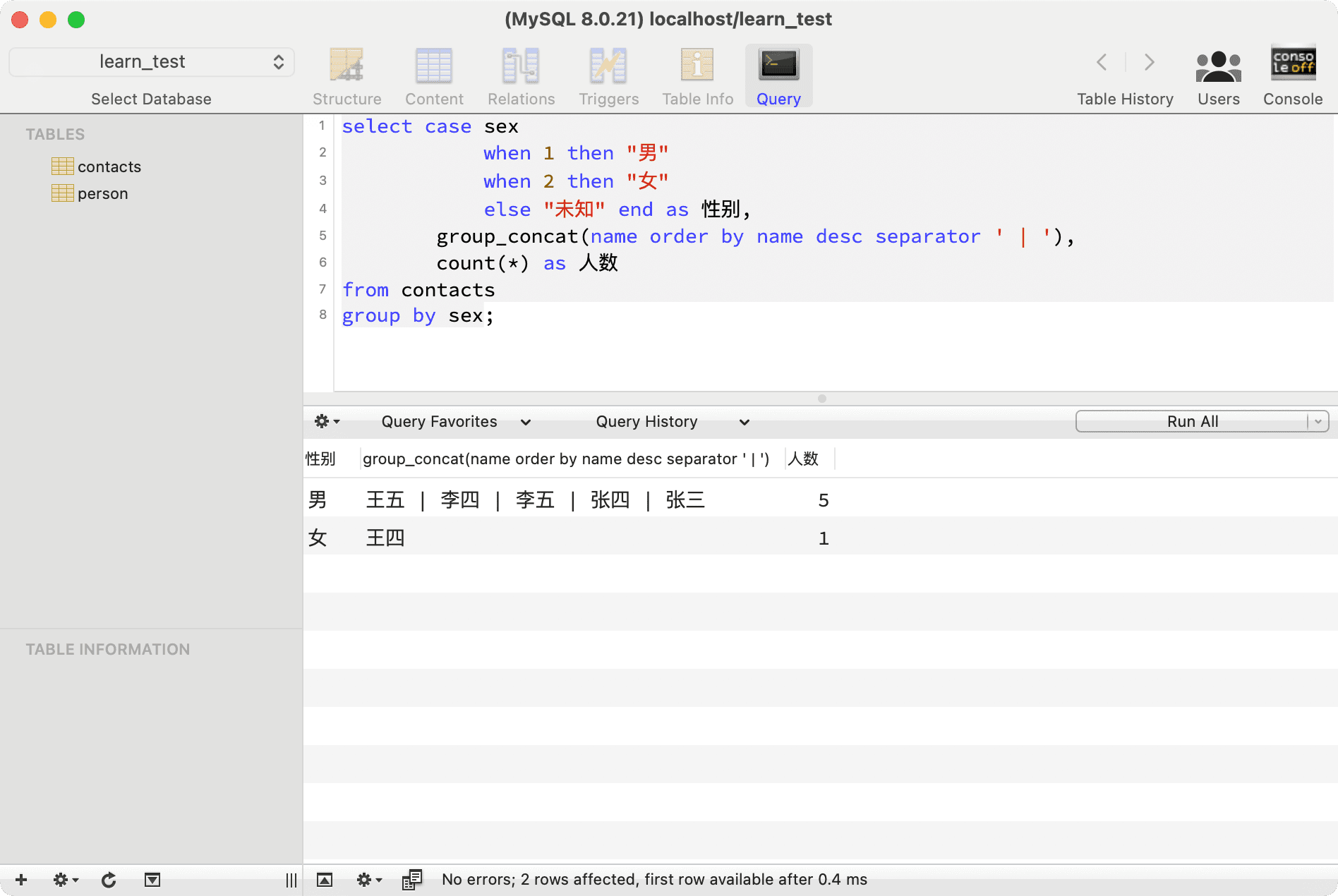
You can also use GROUP_CONCAT to combine specific data:
--- Display a list of contacts by gender and total count
select case sex
when 1 then "Male"
when 2 then "Female"
else "Unknown" end as Gender,
group_concat(name order by name desc separator ' | '),
count(*) as Count
from contacts
group by sex;
Sometimes, we only need to return unique values and remove duplicate data, which can be done using the DISTINCT keyword:
--- Remove duplicates when querying fields
select distinct sex from contacts;
In practical applications, it is also common to rank certain product transaction volumes, arrange some values, or display blog articles in chronological order, which requires the use of the ORDER BY keyword. By default, it sorts in ascending order (ASC), and you can manually set it to descending order (DESC).
Additionally, when databases contain a large amount of data, returning all data at once can consume resources, so the LIMIT keyword can be used to constrain the number of returned records, allowing for pagination as well.
select * from contacts order by id desc limit 5;
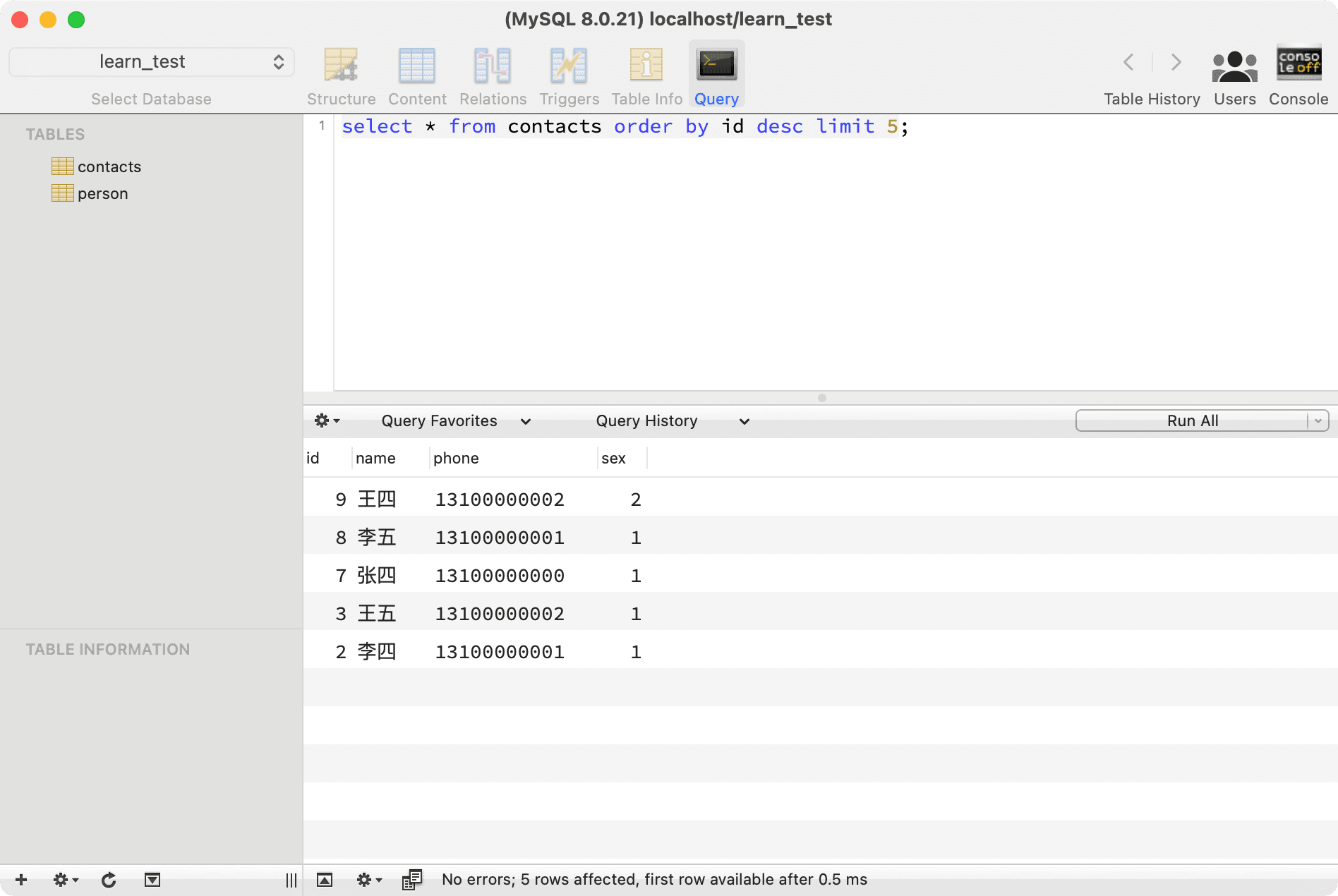
Built-in Functions#
MySQL also has many common built-in functions that help users handle various data more conveniently and simplify operations. Most functions are intuitive and will not be explained in detail.
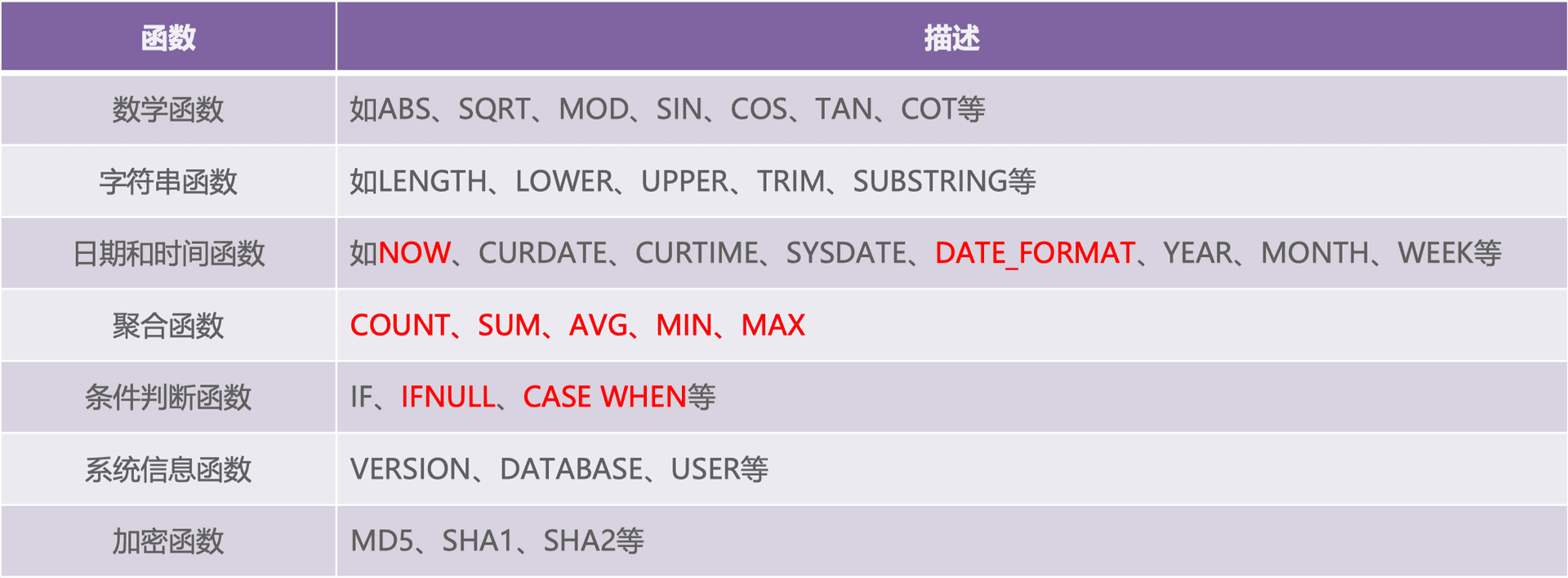
Notably, aggregate functions perform calculations on a group of values and return a single value.
Flow Control#
MySQL has flow control statements similar to if-else or switch in programming languages to implement complex application logic:
--- Select data and label gender in Chinese
select name, phone, case sex
when 1 then "Male"
when 2 then "Female"
else "Unknown" end
as sex
from contacts;
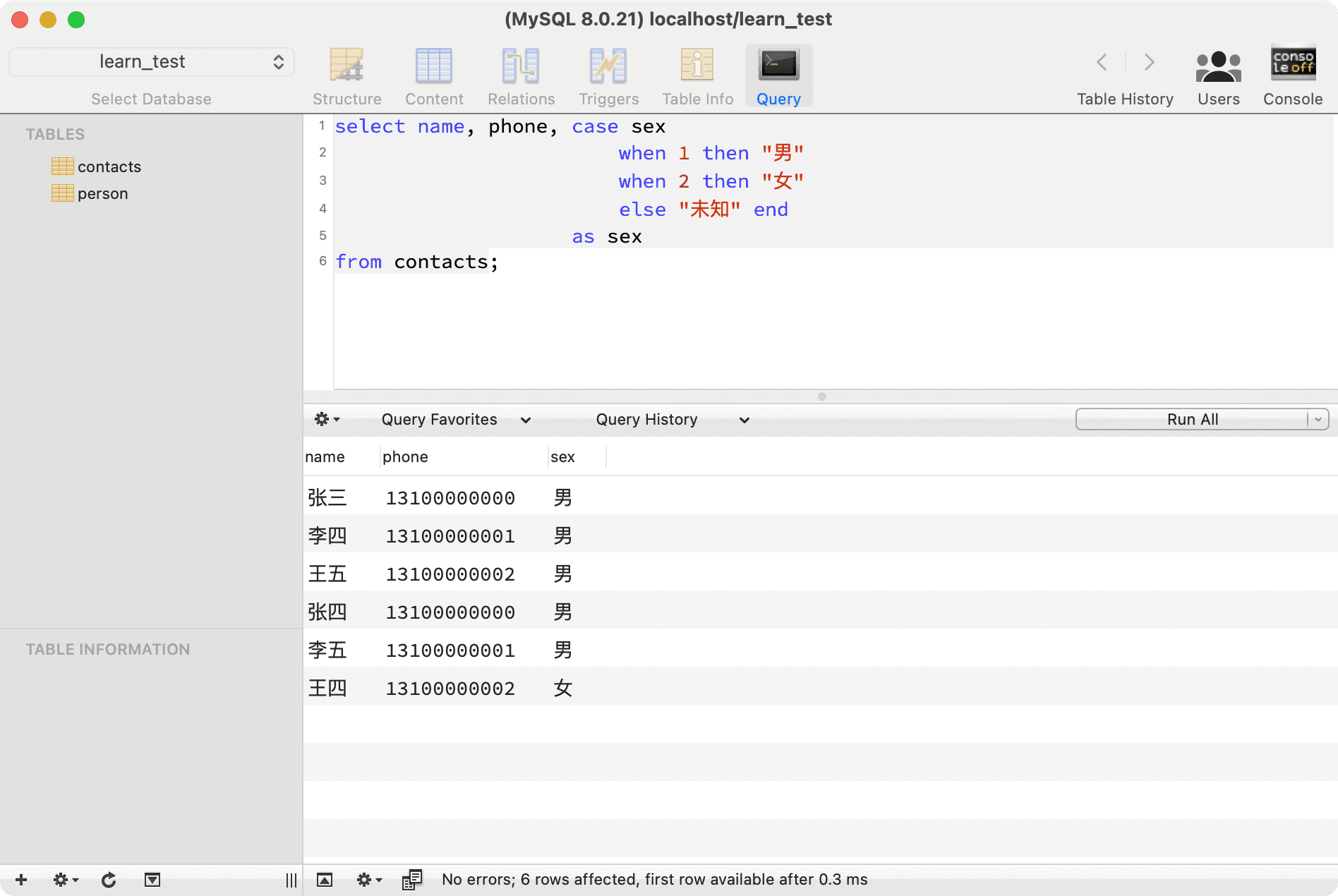
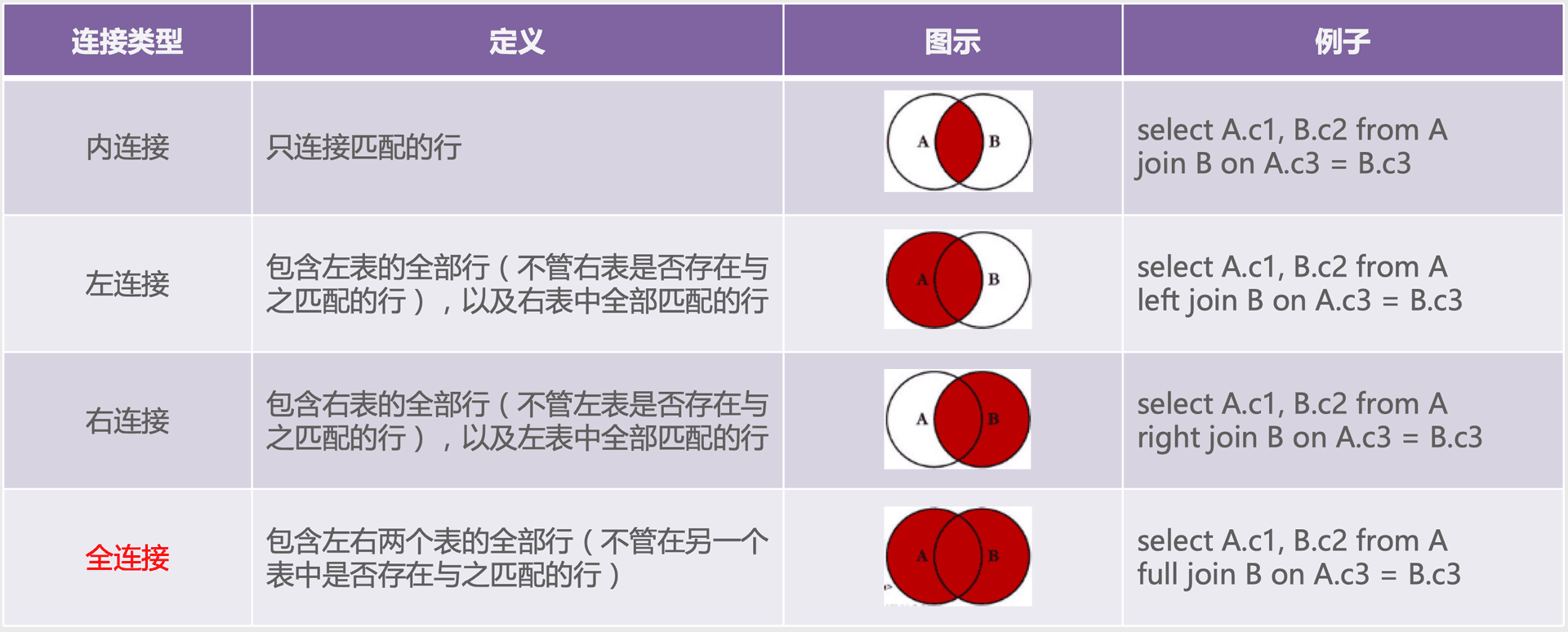
Table Joins#
Different tables can be associated through certain join conditions, mainly including self-joins, inner joins, and outer joins, with outer joins further divided into left outer joins, right outer joins, and full outer joins. Their differences are as follows:
Self-join is a special type of join that logically generates multiple tables to achieve complex hierarchical structures, commonly applied in region tables, menu tables, and product category tables. The syntax is as follows:
--- Self-join syntax
select A.column, B.column
from table A, table B
where A.column = B.column;
Conclusion#
Having learned about relational databases, what about non-relational databases? In the future, we will organize information on Redis, a widely used non-relational database, so stay tuned!